Cloud DCN 3.0构筑高性能智算网络,决胜算力时代
发布时间:2023-08-21
作者:中兴通讯 夏迎春,周昆
算力已成为数字经济发展的重要引擎。随着数字经济的飞速发展,以及各种新业态、新数字需求的不断涌现,算力需求规模越来越大,算力呈现多层次、多样性发展趋势。近5年,算力总规模年均增速超过25%,并随着人工智能(AI)技术的发展,各种新型智能应用爆发,以AI为特征的智能算力发展速度远超通用算力。据IDC预测,未来5年,我国智能算力规模的年复合增长率将达50%以上,数据中心的算力时代已经到来。
未来80%的经济场景将是基于人工智能或应用人工智能,所消耗的算力由智算中心承载,而传统的以提供虚拟化资源服务以及通用算力的传统云计算数据中心已无法满足各行各业对于智能算力服务的需求。智算中心利用人工智能、大数据、云计算等技术来提高数据中心的处理能力和效率,是未来数据中心的演进方向。
智算中心网络的挑战和关键需求
智算中心网络的需求和演进受AI模型影响巨大,不同的模型对网络的需求和挑战不同。AI模型大致可分为决策/分析式AI和生成式AI。
决策/分析式AI模型训练参数规模小,所需算力小,10台以下GPU服务器就能满足需求,这种模型的引入不会改变现有云计算网络的架构。
生成式AI的参数训练数量达到千亿以上,采用大规模GPU服务器集群。生成式AI也因此被称为AI大模型,智算中心网络的主要挑战来自于AI大模型。大模型训练网络具有以下流量特征和关键要求:
- 数据并行、模型并行
在AI大模型训练中,为了提高训练效率以及解决单卡无法加载大模型的问题,需要采用同时数据并行和模型并行。其中数据模型是把训练样本集拆成多个mini-batch,在多个AI节点上并行训练,节点之间需要梯度同步参数,通信模式以All-Reduce为主;模型并行是将模型切分为多个子模型,存放在多个AI节点,突破GPU显存容量限制,实现大模型,其中Tensor模型并行的通信模式All-Reduce为主,Pipeline以P2P为主。
- 通信量大、大流同步突发多
不同于云计算环境中CPU大部分时间用于内部计算,在AI大模型训练中,GPU通信时间占比达到50%以上,节点内的GPU通信带宽达到600Gbps级别,节点间通信带宽达到100Gbps级别。同时,大模型训练网络中的流数量少,单流带宽大,同步突发概率高。
- 内部高速总线、网络多轨同步
GPU服务器内,通过NVlink/NVSwitch/CXL等总线技术实现服务器内高速通信,通信速率达到几百Gbps;不同于云计算,GPU服务器间的通信关系明确,不同服务器间相同编号的GPU互相通信,此特点为大模型训练提供了多轨道流量聚合型网络架构的创新设计依据。
- 网络时延敏感
在AI大模型训练中,集合通信的网络时延性能和业务吞吐性能呈现正相关,决定训练加速比的上限。目前网络动态时延高出网络静态时延几个数量级,网络时延抖动对业务吞吐性能影响巨大,90%的长尾时延降低可以带来3倍以上的吞吐性能提升,动态时延是约束业务吞吐性能的主要矛盾。
- 网络故障敏感
对于千卡级的GPU训练集群,网络的可靠性直接影响整个GPU集群的计算稳定性。相比GPU故障只影响集群算力的千分之几,网络故障会影响数十个甚至更多GPU的连通性。维持网络的稳定可靠,是GPU训练集群在工程应用中的关键要求和挑战。
-自动化要求高
大模型网络交付涉及的环节多、组件多且场景相关调优工作复杂,依赖多维度自动化能力建设,需要从基础网络环境构建到RDMA网络性能测试、NCCL参数库性能测试、模型性能测试、系统可靠性测试、业务应用交付、工程运营维护提供全生命周的自动化技术和工具支撑。
中兴通讯数据中心网络解决方案CloudDCN 3.0
中兴通讯基于20多年的数据通信技术积累和实践应用,基于内部的三大基础研发能力构建面向AIGC(artificial intelligence generated content)市场的新型数据中心网络产品,推出拥有五大核心能力的算力时代数据中心网络解决方案CloudDCN 3.0,旨在打造高带宽、低时延、无阻塞的算力网络,助力新兴算力业务的快速发展(见图1)。
中兴通讯数据中心网络产品的三大研发基础能力:
- 自主研发的可编程硬件平台:中兴通讯具备完整的芯片自主研发设计能力,COT模式(customer own tools)使芯片设计做到安全可信。目前数据中心网络产品的CPU、交换、转发三大核心芯片已全部自主研发。
- 云原生操作系统:新一代自主研发的网络设备操作系统JiNOS在模块化、组件化、微服务的软件架构方面进行了全面升级改造,可以更好地适应云网融合和云数一体的发展需求。
- 管控一体平台:集网络管理、控制、分析、自智功能于一体的ZENIC ONE控制器,支持对数据中心网络的规划、建设、维护、优化的全生命周期管理。
基于以上三大研发基础能力,中兴通讯数据中心网络解决方案CloudDCN 3.0具有超高带宽、超融合网络、端网协同、网络自智、安全可信五大核心能力。
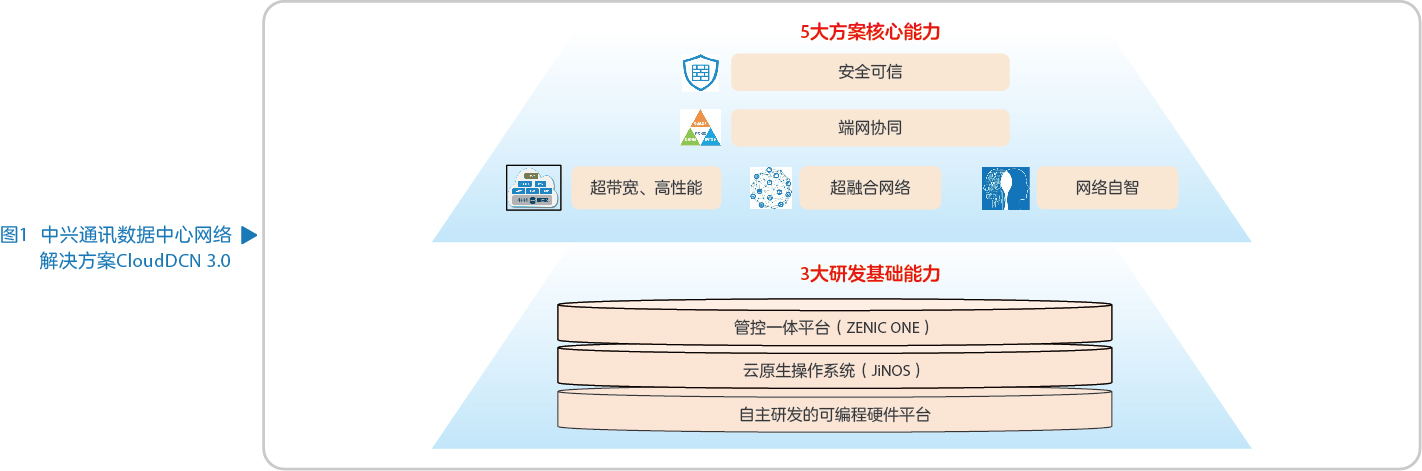
超带宽、高性能
基于中兴通讯数据中心交换机产品,可为运营商、政企行业客户构建面向AIGC业务应用的超带宽、高性能算力网络。
- 超带宽:针对计算(训练)、存储、业务(推理)可分别构建独立的高性能网络区域,并根据业务对网络带宽的要求来选用100G、400G Fabric组网方案,支持平滑演进至下一代800G Fabric;
- 大规模:根据客户业务应用场景的不同,可提供从千卡级300PFlos/POD中型规模到万卡级5EFlos/POD超大型规模不同规格的智算中心组网方案,提供100G和400G混合接入的异构组网能力;
- 高性能:通过新型动态负载分担算法将业务流量动态分担到最优网络链路上,最大程度保证成员链路间的负载均衡效率,避免负载不均的网络拥塞丢包导致计算效率的下降,提供低抖动的微秒级网络时延质量。
超融合网络
作为算力基础设施的重要组成部分,数据中心网络贯穿数据存储、计算与应用的全流程。中兴通讯的超融合网络解决方案为客户提供全以太化网络架构演进,可帮助客户打破原有网络的协议、产品与方案的使用限制,提升算力能效比,降低建设和管理成本。
- 传统数据中心内烟囱式的三张物理网络走向统一,计算(训练)、存储、业务(推理)三网分别从IB、FC、以太过渡到统一的RoCE无损以太网方案,实现三网业务流量的融合承载;
- 根据计算、存储、业务对网络质量要求的不同,可灵活选择25GE、100GE、400GE不同形态的网络设备,最佳匹配客户的算力业务需求;
- 引入RoCE(RDMA over converged ethernet)无损以太网技术,通过PFC流控和ECN拥塞控制技术,让原有的以太网支持RDMA(remote direct memory access),满足算力网络的高吞吐、低时延、无丢包的网络质量要求。
端网协同
由于算力业务流量的随机性以及路径的多样性,网络拥塞的风险不可避免。传统的DCQCN拥塞控制策略以被动拥塞控制为主,且缺乏精细化的流量拥塞控制能力。中兴通讯端网协同拥塞控制方案可为客户提供高精度流控的网络性能:
- 借助IOAM(in-band operation administration and maintenance)性能测量任务,在网卡、交换机上采集和传递比ECN(explicit congestion notification)更精细的拥塞控制信息,提高调速的准确率,减少试探耗时;
- 通过Native IP的源端路径控制技术,端侧进行更精准的调控速率,实现满带宽、低时延、快收敛的网络质量目标,有效提升网络的传输效率。
网络自智
数据中心网络拓扑结构的发展,推动了计算、存储、网络的深度融合,这使得数据中心网络管理变得越来越复杂和重要。中兴通讯的网络自智方案旨在为客户构建自配置、自修复、自优化的网络,提供零接触、零等待、零故障业务网络使用体验。
- 通过管控一体的ZENIC ONE控制器,对数据中心网络提供从网络规划、工程建设、运营维护到网络优化四个阶段的全生命周期管理,为客户提供其极简网络设计部署、业务精准上线保障、故障智能修复与预测、网络自动优化调整;
- 通过交换机设备和控制器内置的AI智能引擎,可以提供智能ECN水线调优、网络日志自动采集、故障根因智能分析、典型故障自动愈合等L3+网络自动驾驶能力。
安全可信
当前,产品和方案的安全可信是关乎企业能否持续稳定提供业务服务的关键要素。中兴通讯通过BCM(business continuity management)战略打造安全供应链,保障战略产品商业可持续,从核心技术自主可控、自主产业链协同发展、战略物料安全储备、资源多样化布局多个维度确保可持续发展能力。
中兴通讯CloudDCN 3.0解决方案所配套网络交换机产品的CPU、转发芯片、交换芯片三大核心器件已实现100%自主研发,产品的功能、性能、能耗等方面已达到行业领先水平。
中兴通讯是国内工业级嵌入式实时操作系统领域的领军者,拥有20年路由操作系统研发/商用积累,针对算力时代的网络设备,推出了完全自主知识产权的微内核、多进程、模块化、分布式的网络操作系统,安全、稳定、可靠。
中兴通讯基于CloudDCN 3.0为客户打造高性能、超融合、端网协同、网络自智、安全可信的智算中心网络解决方案,支撑客户AIGC等新兴算力业务的快速发展需求。当前,中兴通讯已发布千卡级GPU/单POD资源池业务规模的全盒式400G Fabric网络解决方案,2024年即将发布新一代400G Fabric产品,满足万卡级GPU超大规模组网需求,同时提前布局下一代800G Fabric,全力协助客户应对持续增长的业务发展诉求。
.png)

.png)

.png)


