新型智算,助力AI无限可能
发布时间:2025-03-27
作者:中兴通讯算力及核心网产品规划首席专家 郭雪峰
AI技术质变,重塑世界
人工智能技术飞速发展,已成为新一轮科技革命和产业变革的核心驱动力。从基础科学研究到日常消费应用,人工智能的影响无处不在,正在重塑我们的世界。
规模带来质变,Transformer大模型架构正从语言处理领域向计算机视觉、语音识别、结构化数据、时序预测、多模态等更多领域拓展,并助力相关领域模型能力巨大飞跃。如在多模态领域与Transformer结合的MM-LLM(multi-modal large language model),在模态类型的扩展性、应用场景的泛化性、理解和生成能力,以及数据适应性、零样本及少样本学习等方向表现优异,取得显著进展。时序模型与Transformer结合,提升了预测精度、异常检测能力,在电力领域负荷预测及能源调度优化、气象领域天气与灾害预测等应用场景中有巨大潜力。
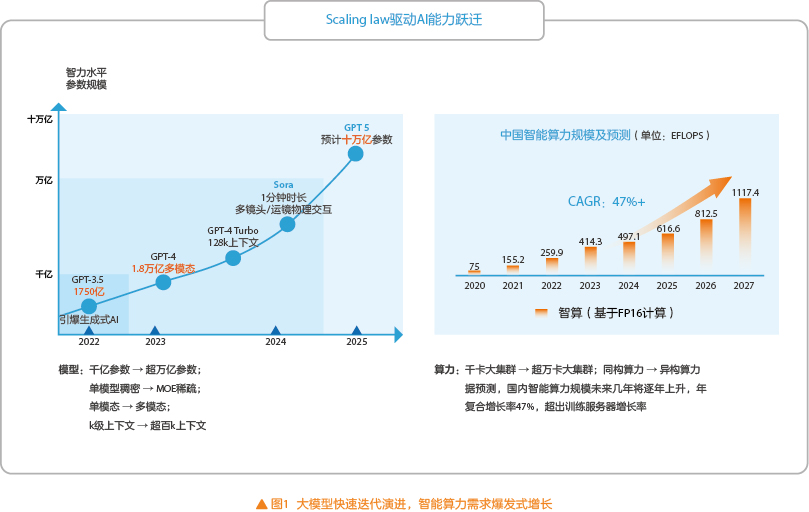
模型和算法快速演进,从单一规模扩张转向多元拓展优化。一方面如图1所示,Scaling law法则驱动大模型参数继续从千亿迈向万亿。另一方面,新的架构和算法不断涌现,如基于混合专家(MOE)架构的稀疏模型脱颖而出,大幅降低大模型的计算成本,随着Scaling law递减效应的出现,促使研究人员探索新型神经网络结构,提高训练数据质量,研究新的训练方式。
训练创造能力,推理实现价值,AI应用正在深度渗透各行各业,无论是传统领域赋能还是新兴领域拓展均展现出巨大潜力。在传统领域赋能方面,AI医疗、AI教育、AI办公、AI通信乃至AI制造等应用场景不断涌现,改善用户体验,提升业务效率。在新兴领域,内容生成、新闻写作、影视创作、创意延申、虚拟形象、数字人播报、多媒体交互正在创造新的变革和生机。随着AI应用的快速落地,推理算力需求长期增长,增长率未来将超出训练算力。
人工智能的发展才刚刚开始,未来发展将超出我们的想象。
新型智算成为AI发展的核心引擎,助力产业升级
人工智能以数据为原料,以算法为引擎,以算力为动力。大模型的成功是Transformer算法与异构并行算力共同发展的结果,人工智能的快速发展,也给智算基础设施提出了新的能力要求。
训练方向,模型规模不断扩大,训练周期持续缩短,万卡、超万卡智算集群正在成为标配,大规模及高算效是核心需求。
算力层,由多类型计算芯片(如CPU、GPU、DPU、TPU等)组成的超异构融合计算成为主流,需要解决的核心挑战包括:大规模海量算力器件的统一纳管和一体化运维、面向多场景多要素多目标的最优算力资源调度、面向大模型训练的长稳可靠集群算力保障,以及跨厂家跨型号异构算力的兼容等问题。
网络层,高速互联的超大规模组网成为必备需求,优化设计Scale-up及Scale-out网络,提供超大规模、超大带宽、超低时延的卡间、机间,以及跨DC间的无损高速网络成为业内主要技术发展方向及竞争焦点。
存储层,存储效率的提升是超万卡训练集群效率提升的关键,需要构建大带宽低时延的热存储,降低模型训练中间文件读取时间,满足预训练海量语料的超高IOPS读写需求,通过冷、温、热一体化分级存储实现成本与性能双向优化。大模型的训练周期长,构建长时稳定的训练算力是必要保障,这对集群整体的可靠性提出高要求,集群资源应可管可视,故障能够快速定位、隔离、修复,能够提供高效的Checkpoint和断点续训方案,缩短模型训练中断时间,实现资源管理的自动化与智能化。AI框架及平台为大模型训练提供全栈工具、算子开发及调优,实现模型训练全流程的自动化和工程化,同样是提升大模型开发训练效率的重要保障。
推理方向,高成本是大模型应用的核心痛点,需要为多场景的应用需求提供最优性价比的推理算力。首字时延、字间时延、吞吐量是推理业务的核心指标,算力、显存大小及带宽、生态兼容是影响推理性能的核心要素。首先在算力选择上,需要基于业务指标需求选择合适的算力资源,实现性价比最优。其次,对模型和应用的兼容至关重要,通过提供统一的推理服务API接口提升应用可移植性,通过兼容多推理引擎实现多硬件适配,通过自动化模型转换、算子生成工具提升模型迁移速度,降低迁移成本。推理技术当前仍处于快速发展阶段,需要持续探索,通过多维度优化不断提升推理性能,降低成本,如系统层面多流水推理调度、KV缓存、P/D分离等技术大幅提升大模型推理吞吐降低时延;模型层面利用压缩技术,在不损失精度前提下加快推理速度,通过图优化、算子优化及算子融合,减少内存访问,提升推理性能。边缘推理、端侧推理以及云边端的协同推理技术正在快速演进,推进推理算力成本快速降低,普惠化发展。
新型智算是算力、存储、网络多要素协同,软件、硬件多维度调优的超大规模集群算力,是能为大模型训练提供极致性能,为多场景推理提供极致性价比的高效算力,能提供从算力租赁到模型训推多模式、多租户、多任务精细化运营的全栈智能算力服务,助力实现人工智能技术的创新应用与产业落地,驱动数字经济高质量发展。
开放解耦,构建国产化智算发展之路
当前,我国智算产业与国际先进算力相比仍有较大差距,尤其在高端芯片方向,无论是计算性能、制程工艺还是生态构建上均存在较大短板,领域内存在多框架、多软件栈、多芯片,群雄并起,多而不强。这种碎片化的行业态势使得跨厂家跨型号异构算力难以互联互通,无法形成合力,不利于智算的长期健康发展。
面对以上挑战,中兴通讯提出自主创新、开放解耦的新型智算发展之路(见图2)。在超大规模集群构建上主张以网强算,以规模换算力,在业内率先提出Olink开放互联总线技术并推动构建统一的开放互联标准,发布400G大容量国产化智算网络解决方案,为大规模算力互联提供网络基础,助力算力集群大规模互联及平滑扩容。在异构算力兼容及增强方向,强调软硬解耦,以软强算。在芯片使能层面通过算子优化、算子增强充分释放芯片算力,在集群使能层面通过一体化的编排调度屏蔽算力差异及集群可靠可用性,在AI平台层通过优化断点续训、超参寻优、多流水任务调度等手段最大化集群算力利用率。在生态构建上强调模型解耦、训推解耦,通过为上层应用提供一致的模型接口降低应用开发及迁移成本,促进应用生态繁荣,通过提供全栈训推迁移工具赋能模型跨框架/跨硬件迁移,促进模型兼容生态;通过异构混池算力拉远实现跨厂家/跨型号算力互联互通,促进算力生态兼容。同时,中兴通讯大力推进统一的智算标准制定工作,助力构建开放解耦的智算生态。

人工智能的长期发展必须建立在兼容、高效、开放的新型智算基础设施上,推进统一的智算互联互通标准,以开放解耦为基础形成合力,促进产业健康发展。中兴通讯将继续携手业界先进合作伙伴,成为推进人工智能发展进步的核心力量,为人类创造更加美好的未来。
.png)

.png)

.png)


