“数据要素×AI”——数据基础设施助力大模型高质量发展
发布时间:2024-11-04
作者:中兴通讯 王继刚,陈靖,刘丰
大模型面临的数据供给挑战
人工智能大模型的发展,离不开高质量的语料数据集,如何获得高质量数据集、保障训练数据集安全采集、充分发挥数据价值,已成为大模型发展不可避免的问题与挑战。
- 挑战一:公开数据量有限。互联网上虽然存在大量文本数据,但其中很多都是低质量的,如垃圾信息、广告宣传等。而且公开数据集只能解决通识问题,细分行业的专业性问题,公开数据无法提供参考。
- 挑战二:行业数据壁垒高。对于一些垂直领域,如科技、医疗、金融等,数据往往涉及商业机密或隐私信息,很难对外共享。例如在自动驾驶领域,出于商业秘密保护,各企业独立进行道路数据采集,很少进行数据共享。这不仅导致大量重复性工作,降低了自动驾驶算法研究的整体效率,同时每个企业采集的数据在路况、天气等方面都有局限性,无法做到更广泛情形的覆盖。
- 挑战三:数据采集成本高。高质量数据往往需要经过采集、标注和清洗才能使用,这需要投入大量的人力和物力。提高大模型开发过程中数据供给、生成高价值训练数据集成为大模型发展的迫切需求。
国家数据局等17部门联合印发的《“数据要素×”三年行动计划(2024—2026年)》,进一步明确“建设高质量语料库和基础科学数据集,支持开展人工智能大模型开发和训练”。通过数据要素建设推动人工智能大模型发展,可以有效解决人工智能,特别是大模型研发所面临的数据瓶颈,进一步发挥大模型对于知识数据的汇集和处理能力,创造更大的生产力,助力数字经济新发展模式。
构建数据基础设施,提升大模型的数据供给规模和质量
数据基础设施是从数据要素充分流通并释放价值的角度出发,在网络、算力等设施的支持下,提供一体化数据汇聚、处理、流通、应用、运营、安全保障服务的一类新型基础设施,是覆盖硬件、软件、标准规范、机制设计等在内的有机整体(见图1)。中兴通讯的数据基础设施通过隐私计算、区块链、数据脱敏、数据空间等技术,实现数据在不同主体间“可用不可见”“可控可计量”,为不同行业、不同地区、不同机构之间的数据实现合规高效流通,整体推动数据服务千行百业、深度融入社会生产生活,推动数据要素“供得出、流得动、用得好”,有效提升数据流通环节的安全可靠水平。
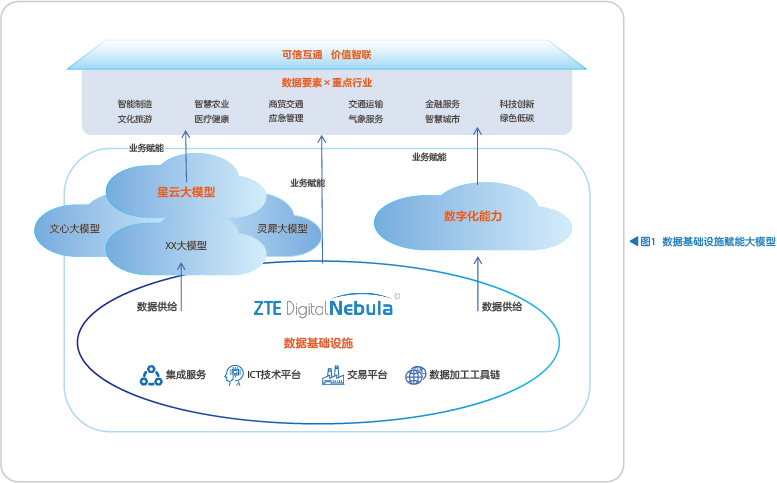
在“数据要素×AI”场景下,通过数据基础设施提供的智能分类分级、数据脱敏、隐私计算、区块链以及一站式数据处理等数据集构建能力模块,打造适配各种大模型的数据供给方案,实现了大模型训练语料数据的可信收集,全生命周期数据安全可控,消除了高价值数据拥有方的供给顾虑。核心能力组件包括:智能分类分级、数据脱敏、隐私计算、一站式数据处理。
- 智能分类分级
支持各数据源数据资产的自动发现与动态更新,多数据源、多类型数据的自动分类分级等。中兴通讯数据基础设施的数据分类分级工具内置了政务、交通、工业等10余项行业数据分类分级标准,在智能分类分级过程中更加贴合行业属性。
- 数据脱敏
通过数据脱敏机制对语料中包含的敏感信息应用脱敏规则进行数据的变形,实现敏感数据的可靠保护,在不影响数据分析对数据要求的条件下,对数据进行改造并提供使用。中兴通讯数据基础设施的脱敏组件可支持50种以上的数据脱敏算子,满足各种不同行业数据使用场景下的数据脱敏需求,以便在数据标注、预处理等非生产环境以及外包环境中,可以安全地使用脱敏后的真实数据集。
- 隐私计算
在多个大模型研发参与单位,分别部署隐私计算计算节点进行本地数据的读取,基于同态加密、秘密分享、不经意传输、零知识证明等密码学算法,在多方原始数据不出本地数据库的前提下,完成多方联合训练任务。能够实现大型企业在研发大模型语料收集阶段的分布式安全采集,既保证了大模型语料的质量,也保障了各研发单位原始数据的安全性。中兴通讯隐私计算和区块链平台是首家通过信通院“代码自研率”“国产环境兼容性”测试的企业。
- 一站式数据处理
多源异构原始语料管理、数据集管理、数据标注和预处理等功能,形成高质量数据集(见图2)。
首先明确数据集的数据类型、数据量和数据质量要求;根据数据集目标确定数据采集策略,确定数据采集的来源、方法和频率;采集到的原始数据往往存在噪声、缺失值和异常值等问题,采用低质站点过滤、异常符号过滤、脏数据过滤、文档级去重、句子级去重等手段开展预处理;通过敏感过滤、分类精炼等完成数据集的进一步加工,同时通过算法打分、人工打分的方式持续优化数据质量,并进为每个数据样本添加正确的标签或类别,最后根据模型训练需求匹配合适的高质量数据集。对数据集进行持续更新和维护,以确保数据集的时效性和准确性。
一站式数据处理组件可高效构建领域数据集与精调数据集,将无序的原始训练数据整合成高质量结构化的数据资产,建立数据画像,丰富数据标签,研究模型专业化流程,在增量预训练、精调训练、模型优化和部署、监控数据、回归测试与模型评估过程中,提高数据的可访问性和可复用率。

- 水印添加和去除
在每份共享的数据集流转各环节上加入水印标识,一旦发生泄漏,即可根据水印隐藏的信息确定泄漏源,快速定位责任人。同时,中兴通讯数据基础设施的水印组件在收集数据资产的过程中,当遇到一些影响文本提取效果的水印存在时,可以采用去水印技术去除水印,提升数据提取的质量。
- 基于知识图谱和大模型的知识管理
利用自研的大模型将每份数据资产分解为各个数据子模块,然后利用知识图谱技术对这些子模块进行管理,形成文档树,并将文档树背后的业务信息进行关联,最终将知识图谱中的结构化信息输入到大模型进行训练。
数据基础设施为星云大模型积累大规模、高质量、多元化语料,精炼后超3.5万亿Tokens;数据结构化,建立数据画像,丰富数据标签,数据内容高度可控;利用知识图谱形成文档树并与业务信息关联,实现高效的知识消费。
数据、算法和算力是构建AI系统的三大核心要素,三者的协同使现代AI技术实现了从理论到应用的飞跃。数据是AI的基础,大规模高质量的数据不仅能提高现有模型的准确率,还能促进模型的优化和创新。未来,中兴通讯将持续加大在大模型和数据基础设施领域的研发投入,依托数据基础设施,为各类行业大模型提供包括原始数据集、定制数据集和配套产品工具等在内的整套数据加工服务。
.png)

.png)

.png)


