多样化的AI芯片
发布时间:2024-03-22
作者:中兴通讯 高振中
1956年,在美国达特茅斯学院的夏季研讨会上,麦卡锡、明斯基等科学家首次提出AI概念。此后的60余年中,AI发展历经多次沉浮,经历了漫长的探索期。直到2015年,AI的视觉识别精度超越人类,开始在视频领域规模商用。2022年,现象级产品ChatGPT横空出世,推动大模型成为产业应用的主要方向。
AI芯片是AI发展的重要基石,经历了两个主要阶段。2012年以前,AI研究和应用主要基于CPU;2012年,多伦多大学的Alex Krizhevsky首次将GPU用做AI,只用了4颗英伟达Geforce GTX580(同时期的谷歌方案采用16000颗CPU) 就在ImageNet竞赛中获得冠军,震撼了学术界,开启了AI芯片多样化的大门。
AI芯片的关键需求
从功能上,AI芯片可分为训练芯片和推理芯片两大类。训练,指的是通过向模型提供大量标注或未标注的数据,并基于优化算法来调整模型的参数,使其能够从数据中学习到相关的模式和规律。推理,是指将已经训练好的模型应用到实际场景中,进行预测、分类或决策。
训练芯片的关键需求是如何提供更高的AI算力,降低模型的训练时间。大模型趋势发生以来,模型的数量、规模,在短短几月内剧增,百亿千亿级别大模型飙升至数十个,万亿参数大模型已正式诞生。训练所需的计算量也随之呈指数增长,且翻倍时间约三四个月,远快于芯片工艺的摩尔定律,导致大模型的训练时间不断被拉长。以OpenAI为例,2022年训练一次1750亿参数的GPT-3模型大概需要1024块A100 GPU运行34天,2023年训练一次1.8万亿参数的GPT-4模型大概需要25000块A100运行约100天。相比GPT-3,GPT-4的训练时间增加近2倍。
推理芯片的需求呈现多样化的趋势,主要由业务场景决定。如线上问答场景,AI芯片的算力需要跟上人类的阅读速度(平均每分钟阅读250个单词,最大1000个单词)。如5GC的新通话场景,需要在AI算力的基础上,叠加语音编解码和图像处理能力。
AI芯片的部署位置
AI芯片主要部署在云侧和端侧。云侧一般指云端数据中心,端侧一般指个人可接触或使用,不需要远程访问的设备内(如手机、PC等)。
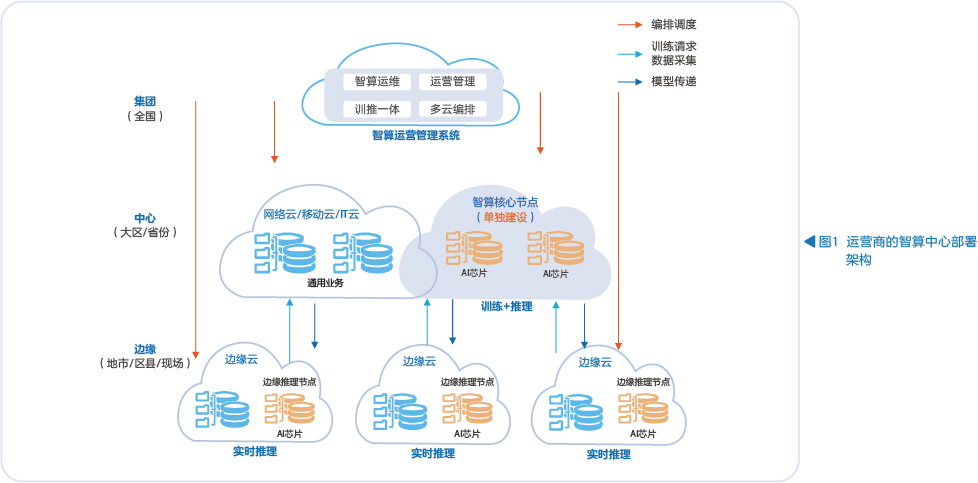
云端数据中心,以运营商的智算中心为例,可进一步细分为集团节点、中心节点和边缘节点(见图1)。集团节点用于智算运营管理;中心节点用于训练和非实时推理;边缘节点与边缘云混合建设,用于实时推理。
端侧AI具备安全性、独立性、低时延、高可靠性等特点,能很好地完成各类AI推理任务。目前,多个大模型均已推出“小型化”和“场景化”版本,其轻量化提供了端侧运行的基础。
AI芯片的技术路线
以GPU为代表的通用并行计算架构以及以针对AI领域加速为代表的专用定制架构,是目前两大主流AI芯片技术路线。
GPU设计初衷是进行图形渲染。图形处理涉及到相当多的重复计算量,因此GPU芯片上排布了数以千计专为同时处理多重任务而设计的图像计算核心,正好和AI运算的数据量规模大、可并行的特点相匹配。
不同于GPU,AI专用芯片是一种针对AI运算的专用处理器,内部以AI专用核为主,相比GPU,减少了视频渲染、高性能计算等功能。AI 专用芯片在功耗、体积等方面有一定的优势,但由于是专用定制的设计思路,开发周期较长,在通用性和可编程性方面也弱于GPU,整体处于多而不强的局面。
未来展望
万亿大模型已成为事实,不远的未来很可能出现十万亿的超大模型。随着模型规模的不断增长,无论是GPU还是AI专用芯片,性能和功耗都出现了瓶颈,导致云端数据中心的规模不断增大,从千卡演进到万卡。功耗不断增加,需要引入液冷才能满足散热要求。另一方面,模型在端侧落地也面临着功耗问题,AI手机和AI PC作为两种典型的端侧设备,功耗的增加都会影响消费体验。针对以上问题,下一代AI芯片设计有以下方向:
在计算架构层面,引入存算一体架构,降低功耗。当前的主流GPU和AI专用芯片均采用冯·诺依曼架构,计算和存储分离,芯片60%~90%的能量消耗在数据搬移过程中。存算一体架构将内存与计算完全融合,避免数据搬移,可大幅降低功耗。
在芯片实现层面,采用Chiplet和3D堆叠技术,提升芯片良率和性能。Chiplet将芯片分割成多个具有特定功能的芯粒(如计算芯粒、存储芯粒等),各种芯粒选择最适合的半导体制程进行分别制造,实现最优的良率,再通过高速总线将彼此互联,最终集成封装为一颗芯片。3D堆叠把芯片从二维展开至三维,在不改变原本的封装体积大小的基础上,通过在垂直方向进行芯粒叠放,增加芯片内的芯粒数量,进而提升芯片性能。
.png)

.png)

.png)


