中兴星云智算网络,新一代高阶智算网络解决方案
发布时间:2025-04-27
作者:中兴通讯 周昆
自2021年ChatGPT 3引发AI智算热潮以来,短短3年时间里,模型参数量便从千亿规模跃升至十万亿级别,平均每年保持10倍的惊人增长速度。随着AI大模型参数量的迅猛增长,所需的GPU集群规模也在同步扩大。目前,国际上已经开展了超万卡甚至十万卡规模的工程建设,例如OpenAI拥有2.5万张GPU卡,特斯拉更是配备了20万张GPU卡。国内由于单卡算力性能存在一定限制,为了追赶国际先进的算力水平,就需要部署更多数量的GPU卡来提升整体算力性能。这使得大规模智算组网能力在国内智算业务建设中的重要性愈发突出。
大规模智算组网的挑战
大规模智算组网作为释放强大算力的基础支撑,其重要性不言而喻。随着ChatGPT、DeepSeek应用的爆发式增长,对智算能力的需求呈指数级攀升。迈向大规模智算组网的征程并非坦途,在超大规模、极致性能以及安全可控等维度,正面临着诸多严峻且亟待攻克的挑战。
超大规模
在Scaling Law(扩展定律)的驱动下,当下万卡GPU训练集群仅仅是AIGC核心参与者的入门标准。随着特斯拉率先宣告十万卡集群投入使用,国内云服务提供商如阿里巴巴、百度等也相继宣称具备支持十万卡集群的能力。可以预见,未来将会涌现出更多十万卡甚至百万卡规模的智算集群。
如此庞大的组网规模必然促使网络技术产生质的飞跃。高性能网络架构的主要功能设计以及性能要求,都需要置于支持超大规模网络的框架内重新审视与考量。
超大规模组网面临诸多主要挑战:
- 单机接入的容量限制
服务器GPU网卡的数量和接口速率呈持续增长态势,基本每两年翻一倍。当前,大规模商用的GPU服务器网卡接口已达8×400G,支持800G的GPU服务器也已面市。为了满足日益增长的接入需求,同时减少设备数量,对单交换机容量的要求越来越高。然而单交换芯片的容量提升速度远落后于IO总线的发展速度,还受到物理层面的限制。
- 组网架构的规模限制
为满足数十万卡乃至更大规模的组网需求,鉴于单台盒式交换机支持的端口数量在短期内难以实现大幅提升,传统的盒式交换机组网架构不得不增加网络层次。但网络层次的增多意味着数据转发跳数增加,这不仅导致路径规划更为复杂,还加大了故障发生的概率以及故障定位的难度,使得网络运维工作更困难。
极致性能
为最大程度提升集群算力利用率,AI大模型训练一般会采用并行处理机制,将单个任务分配到多个GPU上同步运算。并行训练总体可分为处理、通知、同步3个步骤:在处理阶段,每个GPU分别执行任务的一部分;到通知和同步阶段,GPU之间进行卡间通信,汇总得出整个任务的最终结果。整体的作业完成时间(job completion time,JCT)取决于GPU返回计算结果的速度以及网络同步的速度。所以,网络性能对集合通信效率有着重要影响。要实现网络的极致高性能,面临以下挑战:
- 时延方面:动态时延通常比静态时延高出几个数量级,是造成网络低时延问题的主要因素。由拥塞、丢包引发的时延往往达到毫秒级别,因此需要更精确的流量控制/拥塞控制以及故障恢复机制。
- 抖动方面:现有的拥塞控制技术,如DCQCN等,主要针对丢包和吞吐量进行优化,在控制网络抖动方面考虑不足,需要更为精准的拥塞及流控机制。此外,大模型训练产生的流量以大象流为主,若网络负载均衡的粒度太粗,也会使网络抖动难以有效管控。
- 吞吐方面:高吞吐设计是一项复杂的系统工程,涉及到机内外以及软硬件之间的精细协同。单独提升某一项指标,不仅无法有效提高吞吐率,还可能产生此消彼长的负面效应,因为丢包、时延和吞吐这几个因素往往相互影响。
安全可控
在国内各行各业智算业务迅速发展的大背景下,网络产品和技术的安全可控变得愈发重要。将网络安全融入业务流程,提升安全可控的网络产品和技术的可用性,是实现智算业务安全运营的必然要求。满足网络安全可控的需求,面临以下挑战:
- 网络产品器件的供应链安全
智算网络方案与产品涵盖CPU、转发、交换以及内存、连接器、电源、I2C控制器等众多电子器件,只要任何一类器件被独家垄断,就会对产业生态的健康与稳定造成制约。因此,加强核心器件的自主研发,提高外围器件的国产化率,构建稳固且多元化的供应链体系刻不容缓。
- 网络软件系统的知识产权
一方面,网络软件研发过程存在代码复用现象,有侵权风险,还可能引入安全隐患,比如隐藏的后门程序等,一旦被恶意利用,可能导致网络系统被远程操控。另一方面,开源软件在网络领域应用广泛,虽然带来了诸多便利,但部分开源协议较为复杂,如果企业在使用时未能严格遵守,很容易引发知识产权纠纷。如何在合法合规的前提下,强化自身知识产权保护并突破相关障碍,是网络软件发展面临的关键课题。
中兴星云智算网络解决方案
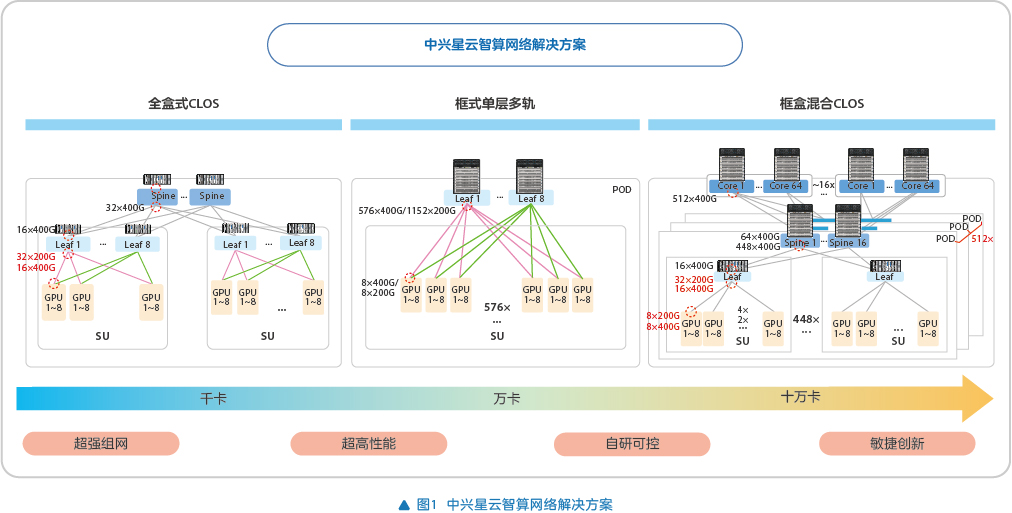
为契合各大运营商以及政企客户在智算业务发展与网络建设方面的需求,中兴通讯创新推出中兴星云智算网络解决方案。该方案依托全自研的ZXR10 5960和ZXR10 9900X智算网络交换机产品家族,为客户打造出具备超强组网能力、超高性能表现、自主可控、敏捷创新优势的新一代高阶智算网络解决方案(见图1)。
超强组网
智算的大模型训练对算力有着极高要求。目前,大模型训练高度依赖大规模GPU集群互联,需要构建大规模网络来支撑GPU并行计算,从而充分释放GPU集群的最大算力。
针对智算网络的参数面、存储面、业务面、管理面,中兴星云智算网络精心设计了超大规模组网方案。这一方案能够全面覆盖从千卡、万卡到十万卡,乃至未来百万卡的全场景智算业务应用。
基于新一代全自研的ZXR10 5960X和ZXR10 9900X智算网络交换机,中兴通讯为客户提供全盒式、单层多轨、框盒混合三大组网架构,客户可根据自身需求灵活选用。其中,框盒混合组网采用多POD(point of delivery)矩阵架构设计,单个POD最大可支持7000张400Gbps的GPU卡集群组网。该架构可依据不同阶段的智算建设规模需求,支持以POD为单位进行灵活弹性扩展,实现分阶段持续建设交付。整个网络最大可支持512个POD,满足未来百万卡的超大规模组网需求。
超高性能
传统RoCE网络中,拥塞和流控算法在端侧与网侧相互独立,网络仅能提供粗粒度的拥塞标记信息。在网络高负荷场景下,这种机制很难保证不出现拥塞丢包以及排队时延的问题。
针对传统RoCE网络在拥塞控制精度方面存在的性能限制,中兴通讯创新性地设计出ENCC(end to network congestion control)这一高精度端网协同拥塞控制技术。通过运用ENCC技术,方案实现了以网络优势助力计算性能提升,端到端网络带宽利用率从60%大幅提升至99%。
在大规模智算组网环境中,存在着大量等价链路,为了充分发挥每张GPU的算力,需要网络充分挖掘每条链路的转发性能,避免出现链路负载不均衡的现象。传统基于Flow五元组哈希的负载分担策略,极易引发哈希极化以及负载不均衡的问题,无法有效保障网络负载分担效率;基于Packet逐包哈希的策略,则会导致报文乱序问题,使其难以在商业场景中得到实际部署应用。
基于上述情况,中兴通讯提出了层次化负载分担架构设计方案。该方案通过不同层级负载均衡机制的协同配合,弥补单一负载均衡方案存在的缺陷,以更好地实现全网流量均衡,并达到高吞吐的目标。
首先,从全局视角出发,设计了智能全局负载分担(intelligent global load balance,iGLB)方案。网络控制器通过API接口,接收算侧调度平台传递过来的流量特征信息,然后依据网络负载状态,对全局路径进行统一规划,以此确保全网每条链路的负载分担效率达到最优水平。
其次,针对模型训练过程中可能出现的局部网络故障或拥塞情况,还配备了自适应路由ARN(adaptive routing notification)技术。交换机可根据本地出口的可用状态和拥塞情况,动态选择出口。在全局规划的基础上,该技术主要针对因网络突发事件导致的瞬时流量不均衡问题,及时对路径进行局部调整。若本地不存在其他满足条件的可用路径,交换机会自动通过数据面报文向上游节点发送通知,促使其进行路径切换,从而实现远端路径的快速调整 。
自主可控
中兴通讯于1996年设立IC设计部,正式启动设备核心器件自研工作,至今已有20余年的持续技术沉淀,中兴通讯已成功量产各类器件100余种,累计发货量突破12亿颗。
在软件方面,中兴通讯早在2002年就着手自研嵌入式OS内核,拥有超20年的操作系统研发及商用经验,具备完全自主知识产权。其嵌入式实时操作系统年发货量超1500万套,累计发货量达2亿套,服务范围覆盖全球130多个国家和地区。
中兴通讯星云智算网络选用的ZXR10 5960X和ZXR10 9900X智算网络交换机,核心器件均采为中兴微电子自主研制。这些自研器件能够完全替代商业器件方案,从根本上化解了核心器件的供应链风险。其中,ZXR10 9900X采用业界领先的CELL/ VOQ交换架构,在设备交换性能上全面超越传统Packet交换架构。此外,中兴通讯还是国内首个完成112Gbps Serdes产品化的厂商,ZXR10 9900X单机最大可支持576个400G QSFP112端口,并且能够平滑升级,以支持576个800G QSFP112-DD端口。同时,针对智算网络交换机的其他外围器件,中兴通讯也全面实现了国产化替代,目前整机的器件国产化率可达到100%。
敏捷创新
中兴通讯星云智算网络依托自研的MASA全可编程技术优势,全面支持P4编程语言。基于自研的PPC+RTC融合架构,数据报文由网络接口接收后,会先经过Pre-Parse报文解析。对于简单业务,可在PPC的多级微引擎流水中进行处理,处理操作包括分类、查表、过滤、修改等;RTC则是完全可编程的微引擎,作为PPC的补充处理部分,它支持在无需替换和修改产品硬件的前提下,仅通过软件编程就能快速适配全新的协议标准和网络特性,这使得产品具备丰富且灵活的无损网络调优能力,能够持续创新智算相关的新特性。目前,中兴通讯星云智算网络已通过敏捷创新,成功支持了中国移动GSE全调度以太网等全新网络方案。
在百度文心、阿里通义、字节云雀、移动九天、电信星辰等国内头部大模型智算业务蓬勃发展的带动下,国内智算中心正快速向超万卡级别的规模迈进,并且部分企业已在规划十万卡规模的智算方案。可以预见,在不久的将来,将会有更多十万卡规模的智算集群相继出现。中兴通讯期待与众多合作伙伴携手共进,共同推动智算网络技术的发展,拓展其应用场景,实现由人工智能驱动的新质生产力的提升,促进社会的共同繁荣。
.png)

.png)

.png)


