智算网络Scale-up技术路线:总线型还是网络型
发布时间:2025-04-27
作者:中兴通讯 李和松
AI技术发展至今,大模型呈现出超百万亿参数、长序列、多模态、推理/测试时计算(test-time scaling)以及物理AI几大明显的发展趋势,可以预见的是,AI对集群算力的需求仍将保持高速增长的态势,智算集群发展到十万卡甚至百万卡规模已成为行业发展的必然需求。在超十万卡规模的智算集群中,由Scale-up网络构成的高带宽域(即业界所说的超节点域)将扮演着重要的角色。以NVIDIA NVL72为例,相比上一代单机8卡服务器,在同等的32k集群规模下,GPT-MOE-1.8T模型推理性能提升30倍,训练效率提升4倍。由于相比Scale-out网络这种明显的业务加速收益,Scale-up网络从2024年开始成为业界研究的焦点。国外以AMD为代表的GPU厂商牵头成立了UAlink技术联盟,而国内短时间出现腾讯ETH-X、中国移动OISA以及中兴通讯提出的OLink(即Open Link)等多种技术方案,并出现了“总线型”和“网络型”两种技术路线之争。这两种技术路线到底是水火不容还是殊途同归,是当前行业关注的焦点问题。
第一性原理看Scale-up网络:核心需求是什么
Scale-up网络作为智算集群所引入的一种新型网络类型,在进行技术路线选择时,首先要明确其核心的技术需求是什么。以当前业界Scale-up网络的行业标杆NVIDIA为例,其NVLink技术目前已经发展到了第5代,最初是为了解决PCIe带宽不足问题而设计的。当GPU之间的通信带宽需求达到300GB/s,为了实现8卡之间的高速全互联,出现了第一代NVSwitch芯片。从NVIDIA官方透露的未来3年芯片规划来看,Scale-up网络呈现出如下发展趋势:NVLink接口带宽逐代稳步提升(NVLink5的1.8TB/s到NVlink 6的3.6TB/s),Scale-up互联规模渐进式提升(NVL576到NVL 1k),随之而来的是其配套的交换芯片NVSwitch的容量同步提升。基于这些基本的技术信息,再综合应用场景的基本特点,可以总结出Scale-up的一些基本特点。
总体而言,Scale-up需要的既不是传统的总线技术,也不是传统的网络技术,Scale-up是具有其特定诉求的新型互联应用场景。任何将总线技术(如PCIe)或网络技术(如以太网、Infiniband等)直接照搬应用在Scale-up场景的做法,都将引入某个维度的性能代价。
Scale-up网络本身是“总线”和“网络”技术在特定场景融合应用的产物,其综合了两者的特点,并融入了自身的核心诉求(见图1)。

一方面,Scale-up继承了总线技术的一部分用户侧需求,如支持Load/Store内存语义、要求控制芯片PPA(performance power area,能效比)代价等,但引入了超高带宽和相对宽松的时延需求。以最新PCIe 6.0×16为例,其带宽只有256GB/s,这与NVLink动辄TB级的通信带宽存在明显的代差。从Scale-up本身的应用场景出发,由于存在计算-通信掩盖等优化技术,Scale-up网络相对而言具有更高的时延容忍度,然而,由于Load/Store语义的同步通信特征,延迟又不能过于宽松。
另一方面,Scale-up网络也继承了网络技术的扩展性需求。由于技术、成本等多方面因素的约束,Scale-up互联规模从最初的8卡发展到如今的百卡,未来有可能扩展到千卡,这种规模需求介于总线互联规模和网络互联规模之间,因此必须借鉴网络技术高可扩展性的设计经验。
此外,由于Scale-up应用场景的特点,为了给上层应用提供一个高效、友好的通信环境,需要支持DMA(direct memory access)语义和内存统一编址,其中DMA语义可有效提升数据批量传输的性能,内存统一编址能为上层应用提供更友好的编程模型。
综上所述,Scale-up的核心需求是TB级超高带宽、k级扩展性、多语义、低功耗、百纳秒延迟以及内存统一编址等。
Scale-up网络技术路线:网络总线化还是总线网络化
鉴于Scale-up网络对未来AI基础设施的重要性,当前业界存在多种技术路线,大致可以分为“网络总线化”和“总线网络化”两种思路(见图2)。
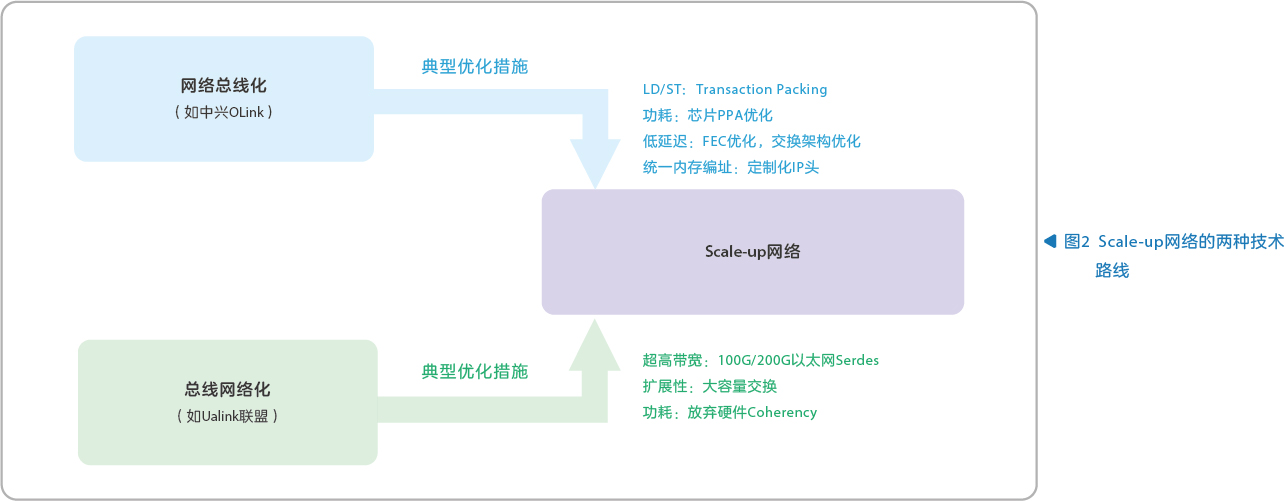
“网络总线化”技术路线
所谓的“网络总线化”技术路线,其主流思路是在传统以太网协议以及交换技术的基础上,针对Scale-up网络的需求开展协议优化以及交换芯片架构创新,从而满足未来一段时间内Scale-up超节点组网的需求。这种技术思路常见于以太网解决方案提供商,其抓住Scale-up高带宽的首要诉求,通过成熟开放、快速发展的以太网生态解决智算“生态封闭”的问题,通过拥抱以太网高速Serdes成熟产业生态解决高带宽互联需求。然而,该技术路线通常需要采用一定的技术手段满足Scale-up网络对延迟性能、低功耗、多语义、内存统一编址等需求,这些工作存在大量的创新空间。中兴OLink是该技术路线的践行者,通过低延迟FEC、LD/ST Packing、内存统一编址、在网计算等一系列创新功能,可以实现Scale-up网络的整体诉求。
“总线化网络化”技术路线
所谓的“总线网络化”技术路线,其主流思路是以传统的总线技术为基础,摒弃一些高代价低收益的总线需求,再引入网络技术元素,满足Scale-up高带宽和扩展性需求。这种思路常见于GPU厂商或以总线技术擅长的厂商,如NVIDIA NVLink和AMD Infinity Fabric。AMD牵头成立的Ualink技术联盟是该技术路线的践行者,其协议主体更多借鉴了PCIe和CXL的设计思想,一方面结合Scale-up的特点摒弃了硬件Cache Coherency的需求,此外,通过在物理层引入以太网Serdes能力,解决了传统总线技术带宽能力不足的问题。
两种技术路线的共性和不同
从技术的角度看,无论是“总线网络化”还是“网络总线化”,其本质都是围绕Scale-up网络的核心需求开展的不同设计,最终都是一个与传统总线和传统网络都不同的特殊网络,过度强调兼容“总线”或兼容“网络”都会带来一些需求或者性能的损失,因此两者并不存在绝对的优劣。
从产业推进的角度看,两种Scale-up技术路线均存在落地上的困难,均需要GPU和网络基础设施进行深度联合设计,且在此过程中,GPU通常处于相对强势的地位。两者的差异在于,“总线网络化”的技术路线更容易被GPU厂商所接受和理解,但通常需求各异难于统一,这加剧了产业落地的难度。而当前数量众多的GPU厂商已经切换以太网接口,这种情况下“网络总线化”反而更容易得到落地。
中兴OLink协议采用“网络总线化”的架构思路,提供完善的端侧IP和交换芯片的产品解决方案,并基于公共以太网技术底座实现Scale-out和Scale-up融合组网,大幅降低了网络建设和运维成本。
Scale-up网络发展趋势和产业建议
从当前AI基础设施发展趋势来看,Scale-up网络将扮演越来越重要的角色,其呈现出如下发展趋势:
- Scale-up网络规模在技术上不断突破,在应用中有序提升
未来几年,随着高速互联技术、芯片工艺、系统工程等技术不断取得突破,Scale-up的理论互联规模将从当前的百卡发展到千卡甚至数千卡的规模,但由于部署成本、边际收益、功耗密度、RAS(reliability,availability,and serviceability)等方面因素的限制,Scale-up实际落地的超节点规模将有序提升,且长期稳定在百卡左右。
- 光互联深入到芯片级,Scale-up网络架构将迎来重构契机
随着电互联逐渐触达香农定律的极限,光互联技术将深入到芯片级,以CPO/Optical IO为代表的技术成为AI芯片的重要发展方向。通过光互联可以极大提升带宽密度并降低互联功耗,服务器、交换机的产品形态和互联方式均发生重大变化,Scale-up网络将迎来架构重构。
- Scale-up和Scale-out网络在协同中融合
随着Scale-up网络和Scale-out网络技术的进一步发展,基础设施层面的融合需求将推动产品技术的进一步靠拢,当Scale-up网络和Scale-out网络在底层技术逐渐从相似走向统一时,Scale-up和Scale-out网络将逐渐融合。
当前Scale-up网络的重要性和技术路线的多样性之间的矛盾显得尤为突出,很多所谓的技术路线之争更多存在于具体的技术方案上,在要解决的核心问题上其实没有根本性的矛盾。在当前智算基础设施产业事实性垄断明显的情况下,中兴通讯呼吁产业界能更多凝聚共识,以“小步快跑”的模式推动Scale-up网络的繁荣发展。
.png)

.png)

.png)


