智算网络Scale-out的演进思路:GSE和UEC
发布时间:2025-04-27
作者:中兴通讯 王恒
在AI人工智能、高速计算等业务迅猛发展的当下,算力需求呈爆炸式增长态势。算力集群正从千卡规模,逐步向万卡、十万卡乃至百万卡规模演进。其中,智算网络作为连接各算力单元的外部纽带,对于能否充分释放整体最大算力、发挥更优算力能效,起着至关重要的作用。
然而,由于所承载业务发生变化,由传统数据中心网络发展而来的智算数据中心Scale-out网络,面临诸多新挑战。
- 智算网络的流量具有低熵、大象流、同步效应等特征,致使传统负载均衡策略难以发挥作用,网络拥塞冲突频发。这大幅降低了网络的有效吞吐能力,进而影响算力效率。
- AI大模型运算依赖多GPU并行计算,多GPU之间存在海量通信,对时延要求极高。一旦发生拥塞,动态时延大幅增加,GPU就不得不等待数据传输完成后才能开展下一步计算,导致其无法满负荷运行,算力无法充分释放。
- RDMA协议采用“Go-back-N”机制,这要求网络必须确保零丢包。一旦出现丢包,进行重传操作,网络的有效吞吐将急剧下降,严重影响算力效率。
因此,如何解决因网络因素导致的AI算力浪费问题,如何让网络与算力更紧密适配,避免网络成为大模型算力的瓶颈,成为智算网络亟待攻克的关键目标。目前,业内各方针对上述挑战开展了诸多努力与探索,催生出各种技术与理念。
结合智算流量的业务特征,各厂家针对RoCE网络开展了大量的增补与优化工作,期望实现“网”与“算”的良好适配。由于不同厂家的主打产品和技术切入点存在差异,该优化路线又细分为网侧优化、端网协同优化等方向。以中兴通讯为例,其iGLB(Intelligent Global Load Balance,智能全局负载均衡)、ZRLB(ZTE Rail Load Balance,端口级负载均衡)等技术,是从网侧视角出发解决负载均衡问题。而谷歌提出的CSIG、阿里提出的HPCC等技术,则采用端网协同方式,端侧借助网侧随路采集的拥塞状态信息进行流量调控,从而有效解决网络拥塞问题。
然而,受现有网络底层逻辑的限制,针对Incast流量拥塞、少流哈希等问题的处理,仅在特定场景下有效,且方法复杂,存在一定局限性。为此,国内外厂家携手合作,尝试对网络进行底层改造,从而衍生出网络架构重构路线。该路线旨在打造全新的网络体系,通过采用新的转发机制,从底层逻辑层面化解当前无损以太网面临的困境,让Scale-out网络在AI人工智能、高性能计算等场景中,能够达成无阻塞、高带宽、超低时延的目标。这一路线的主要代表方案有GSE(Global Scheduling Ethernet)、UEC(Ultra Ethernet Consortium)等。
全调度以太网GSE
2023年5月,中国移动主导提出GSE概念,并联合业界的设备商、芯片商、云服务商、科研院所等机构,旨在针对智算场景,革新以太网基础转发机制,全面提升网络性能,共同打造一个新型的高速无损、安全可靠、开放兼容的网络架构技术体系。
在GSE技术体系中,考虑到智算产业现状与技术发展节奏,其发展分为GSE1.0和GSE2.0两个阶段。
GSE1.0技术,基于现有产品能力,提出了一系列优化RoCE网络性能的技术,如端口级负载均衡、算网协同负载均衡、端网协同的拥塞感知等,这些技术属于对现有网络的改进范畴。
GSE2.0技术,则提出了一系列重新定义下一代网络转发机制与上层协议的技术,比如基于容器的多路径喷洒、基于DGSQ(dynamic global scheduling queue,动态全局调度队列)的拥塞控制等,这些技术属于网络重构范畴。
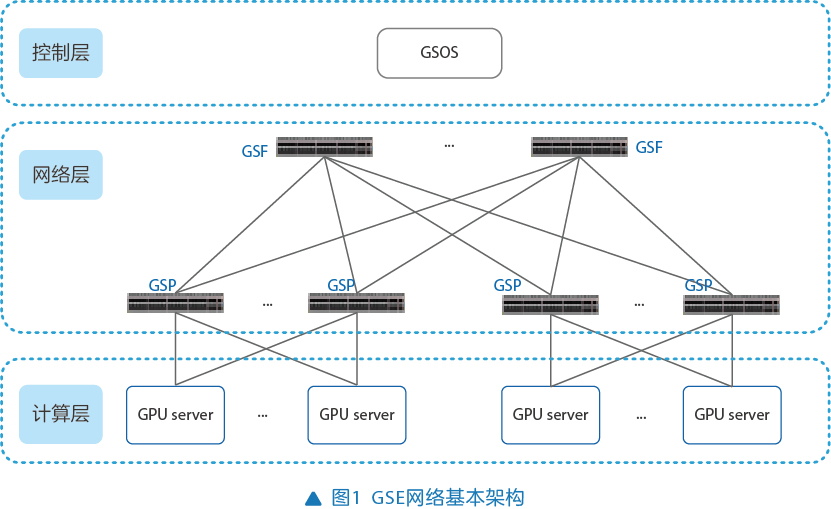
通常所说的GSE,更多是指用于规范下一代网络的GSE2.0技术。在GSE2.0协议标准中,对GSE技术进行了全面阐述,并定义了GSE网络的基本架构,如图1所示:
- 控制层:包含GSOS(global scheduling operating system,全调度操作系统)和NOS(network operating system,网络侧操作系统),主要负责实现全局信息编址、映射等配置与管理功能。
- 网络层:包含源GSP(global scheduling proce- ssor,全调度网络处理节点)、目的GSP、GSF(global scheduling fabric,全调度交换网络)三类设备,这些设备对GSE报文进行识别、封装、解封装以及转发等操作,从而实现全网的流量调度和链路间的负载均衡。
- 计算层:包含高性能计算卡和网卡,作为全调度以太网的服务层。
GSE2.0协议标准提出的核心技术包括报文容器(PKTC)、DGSQ、控制面设计、健壮性设计、网络可视化设计等。
PKTC技术运用主动均衡的理念,构建等长的虚拟容器,并将其作为网络转发的最小单元。如此一来,原有的以太网报文基于流的哈希转发方式转变为基于逻辑容器的多路径喷洒方式,有效解决了因智算流量具有低熵或大象流等特征而引发的负载不均衡问题。
DGSQ拥塞控制技术通过端到端的授权机制,对发往目的端口的总流量进行控制。只有在源GSP收到授权后,才能够发送报文,并且发送的报文数量不能超过授权数量,这从根本上避免了因Incast因素导致的拥塞情况。当源GSP达到设定的水线后,会通知发送源降低发送速率,从而实现流量速率的动态平衡。
控制面设计从全局和分布式两个维度对控制面进行定义,以实现对网络的配置与控制管理。
健壮性设计涵盖故障检测、故障通告、故障收敛等方面。同时提出了更有效的实现方式,比如通过扩展O码来减少故障通告所产生的带宽开销等。
网络可视化设计包括丢包检测、时延检测、根因检测、报文统计等功能,有助于提升网络的运维能力。
超以太网联盟UEC
UEC于2023年7月成立,由Linux基金会主办,汇聚了半导体、设备和云厂商等多方企业,开展全行业合作,旨在构建新一代基于以太网的完整通信栈架构,让超以太网能够更好地满足AI和HPC(high performance computing,高性能计算)对网络的需求。
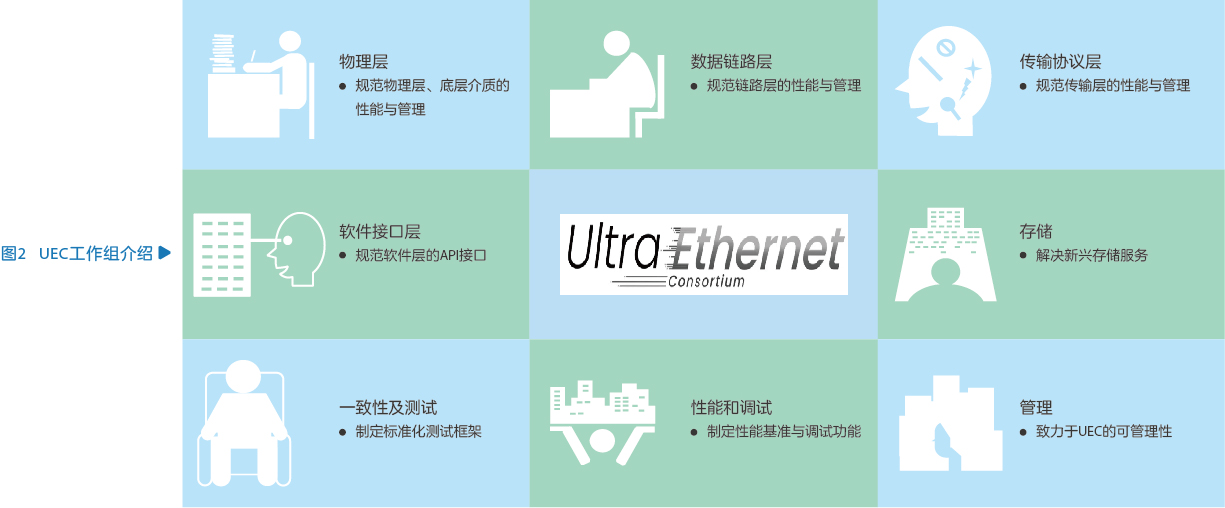
UEC最初设立了物理层、链路层、传输层、软件层4个工作组,后续又相继成立了存储、管理、兼容性&测试、性能&调试工作组(见图2)。这些工作组从不同层面入手,对网络进行改进或重新定义,并提出了一系列关键技术:
- 多路径和数据包喷洒:借助数据包喷洒技术实施路径的精细化负载均衡操作,能够让每条数据流同时利用所有可通往目的地的路径,进而实现网络链路的均衡使用。
- 灵活的排序:对于那些仅关注消息最后部分何时抵达目的地的传输服务场景而言,在将数据包传送给应用程序之前,无需进行重新排序操作。适当放宽对逐包排序的严格要求,能够有效减少数据传输的时延,实现快速且批量的数据传输。
- 优化拥塞控制:为了有效规避Incast拥塞问题的产生,提出了基于接收端的拥塞控制策略。具体来说,由接收端向发送端分配信用值(Credit),发送端依据接收端所分配的信用值以及接收端的实际处理能力,相应地调整数据发送速率。
- 端到端遥测:着重增强拥塞通知的能力,向终端节点提供更为详尽的拥塞位置、拥塞原因等相关信息。同时,提出有效的拥塞缓解算法,使终端节点能够快速感知拥塞事件并做出反应。
当前,智算网络Scale-out尚处于探索的初级阶段,技术路线呈现多样化态势是必然现象。随着实践的持续深入,无论是重点聚焦网侧优化或端网协同优化的优化路线,还是以GSE、UEC为代表的重构路线,乃至其他新兴技术与新生态,其目标都高度一致,即让网络更好地适配大规模算力,为构建新一代智算网络筑牢坚实基础。
.png)

.png)

.png)


