超节点技术:NVL72和ETH-X
发布时间:2025-04-27
作者:中兴通讯 潘文斌
随着人工智能技术的飞速发展,特别是AI大模型参数规模的快速增长,对计算资源的需求呈现出爆炸性增长,需要极高的算力来处理和训练,同时模型的注意力机制和前馈网络都需要大量的内存资源。最理想的方式就是开发一个超级大的GPU,具备超级大的计算能力和内存资源,由这个超级GPU完成所有大模型数据的处理。但现实上是不可能的,业界发展出超节点技术来应对这一问题。目前,在超节点技术领域,英伟达推出了基于NVLink的NVL72方案,凭借其私有协议的优势,实现了高性能的GPU互联;与此同时,ODCC(开放数据中心委员会)则基于以太网RoCE技术提出了ETH-X方案,以开放标准为基础,为行业提供更具兼容性和灵活性的选择。本文重点探讨这两种超节点解决方案的特点与应用场景,深入分析他们在高性能计算领域的价值与潜力。
Scale-up和Scale-out网络
为了应对大模型参数规模的快速增长,可以把大模型分解为两大类,分别处理(见图1)。一类是需要在高频度进行数据交互的,例如张量并行,把这些并行处理放置到GPU之间,通过超高带宽、超低时延互联的网络进行处理,形成一个超节点,压缩超节点内部GPU之间的通信开销成本,这个网络就是Scale-up网络。Scale-up网络是一个追求极致性能的互联网络,支持Load/ Store内存语义。另一类是将数据分解为相对独立的并行任务,如流水线并行和数据并行,这个网络就是Scale-out网络。Scale-out网络利用现有的Infiniband或RoCE网络,支持消息语义。
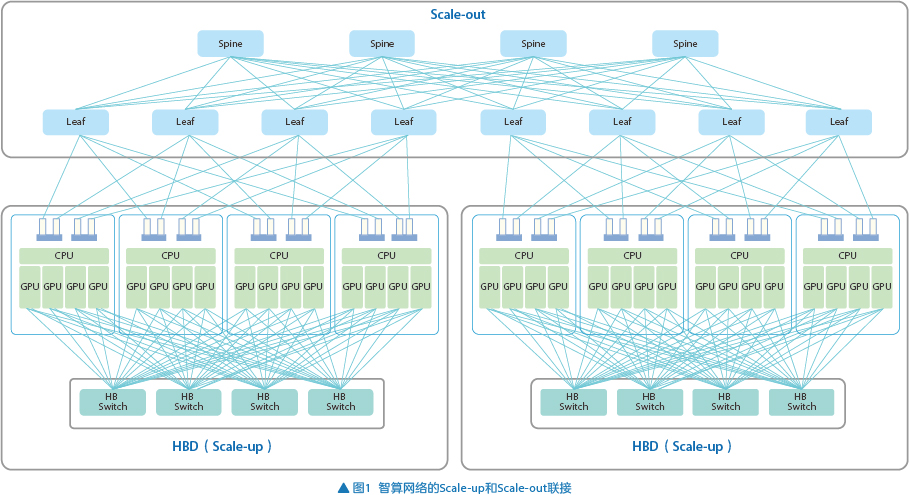
Scale-out网络通过网卡提供对外接口,并借助高性能、高密度的交换机组网实现节点间的互联扩展。当前,常见的组网方式包括框盒组网和盒盒组网,这两种组网方式为超节点在Scale-out方向上的扩展提供了灵活且高效的连接能力。
Scale-up网络则聚焦于超节点内部的深度互联,由GPU内部I/O与HB Switch相结合,形成all-to- all的全互联拓扑结构。在Scale-up连接的技术路线上,业界目前存在两种主要方向:基于私有协议的方案和基于标准开放协议的方案。这些技术路线旨在实现超节点内部GPU之间的高速互联,从而满足复杂计算任务对性能的极致追求。
相较于超节点之间的Scale-out网络,超节点内部的Scale-up网络具备显著的优势:更高的带宽、更低的通信时延,以及更大的缓存一致性内存空间。这些特性使得Scale-up网络能够更好地支持超节点内部密集型计算任务的需求,进一步提升整体计算效率。
英伟达NVL72
NVL72是英伟达推出的机柜级超节点,整个系统由18个Compute Tray和9个Switch Tray构成(见图2)。1个Compute Tray包含2个GB200超级芯片(Superchip),每个GB200超级芯片有2个Blackwell系列的B200 GPU,整个机柜共72个Black- well GPU。同时每个Compute Tray提供4个网络接口卡(NIC)用于Scale-out方向的扩展。1个Switch Tray包含2颗NVLINK Switch芯片,整个机柜提供18个NVLink Switch芯片。整机柜后部通过线缆将Compute Tray和Switch Tray进行互联。
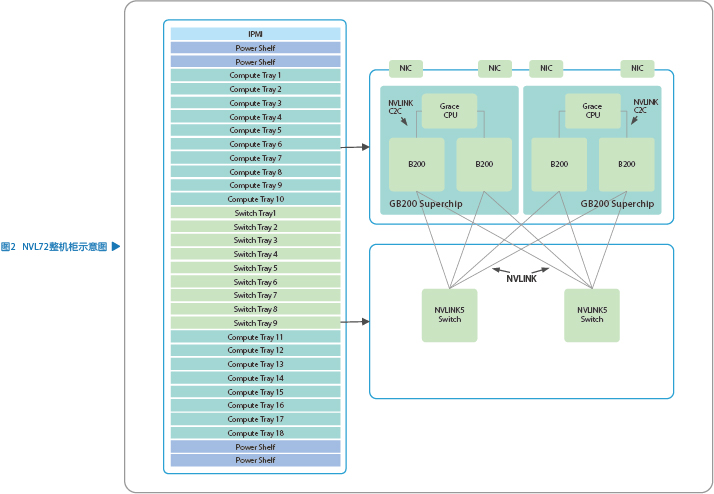
B200采用最新一代的NVLink 5连接方案,对外可提供1.8TB/s(NVIDIA采用双向计算,即单向7.2Tb/s)的NVLink连接,单个Compute Tray提供7.2TB/s(单向28.8Tb/s)带宽,NVL72整机柜的Compute Tray提供129.6TB/S的NVLink带宽。NVLink5 Switch对外可提供7.2TB/s(单向28.8Tb/s)的NVLink连接,单个Switch Tray提供14.4TB/s(单向57.6Tb/s)带宽,NVL72整机柜的Switch Tray提供129.6TB/s的NVLink带宽。这样超节点整机柜Compute Tray的GPU和Switch Tray的交换芯片之间就可以实现全连接。
B200和NVLink5采用200G的serdes,为实现B200的单向7.2Tb/s的带宽,需要72个差分对,NVL72超节点整机柜就需要5184个差分对。Compute Tray和Switch Tray通过机柜后面的线缆连接,每根线缆包含1个差分对,NVL72超节点整机柜需要5184根线缆。
NVL72通过NVLink连接将72个GPU组成一个超大Fabric网络,这个网络解决了GPU之间的高速通信带宽和效率问题,同时通过NVLink,所有GPU都可以任意访问其他GPU的内存空间。另外,英伟达还设计了NVLink C2C,B200和Grace CPU之间采用NVLink C2C连接,创建了一个NVLink可寻址的内存地址空间,B200和Grace CPU之间的内存可以互相访问。通过NVLink和NVLink C2C,每个B200 GPU可以访问超节点其他所有超级芯片的内存,包括B200和Grace CPU。每颗B200提供192GB的HBM3e内存,每颗Grace CPU提供480GB的LPDDR5X内存。这样每个GB200超级芯片提供384GB HBM内存和480GB LPDDR5X内存,NVL72整机柜支持13.5TB的HBM和17TB的LPDDR5X内存容量。
GB200超级芯片的功耗为2700W,每个Compute Tray的功耗约为6.3kW,每个Switch Tray功耗超过800W,NVL72整机柜的功耗预计达到120kW,采用冷板液冷进行散热。
考虑到实际机房提供120kW机柜能力的难度,英伟达还支持规格减半的NVL36。有两种方案:
- Switch Tray结构不变,Compute Tray同样也是有2个GB200超级芯片,包含4个B200和2个Grace CPU,但尺寸改为2U,整个NVL36超节点的Compute Tray数量减半、GPU数量减半,Switch Tray可以有一半的带宽(28.8Tb/s)用于对外连接扩展;
- Switch Tray结构不变,Compute Tray尺寸不变保持为1U,但GB200超级芯片包含的B200数量减为1个,整个NVL36超节点的GPU数量减半,Switch Tray可以有一半的带宽(28.8Tb/s)用于对外连接扩展。
方案2可以提供更大的LPDDR内存空间,但价格会更贵。两个NVL36超节点之间通过ACC线缆互联,同样可以提供72卡的计算能力。通过L2 NVLink Switch进行16个NVL36超节点互联,可以完成Scale-up方向NVL576的扩展,提供576卡的计算能力。
我们来看NVL72怎么满足Scale-up网络的特性的。
- 高带宽
NVL72的每个B200 GPU提供7.2Tbps的Scale-up连接带宽,同时通过PCIe对外提供400Gbps的Scale-out连接带宽,Scale-up带宽是Scale-out带宽的18倍。
- 低时延
英伟达官方没有提供NVLink Switch的转发时延具体数据,但以低时延作为一个卖点,同时从设计上充分考虑低时延的架构。Switch Tray和Compute Tray之间采用的是电缆连接,这样可以节省因CDR或DSP引入的将近100ns的时延,同时也降低了成本。
- 大内存空间
NVL72利用NVLink和NVLink C2C,所有GPU都可以访问整个超节点其他GPU的HBM内存和Grace CPU的DDR内存,NVL72整机柜支持13.5TB的HBM和17TB的LPDDR5X内存容量。
ODCC ETH-X
由中国信通院、腾讯在ODCC牵头发起的ETH-X项目可以支持单个超节点64卡的计算能力,和英伟达的私有NVLink方案不同,ETH-X采用更为开放的RoCE方案。
整个系统有16个Compute Tray和8个Switch Tray。每个Compute Tray包含4张GPU和1个X86 CPU,CPU和GPU之间通过PCIe Switch对接。整个机柜共64张GPU。同时每个Compute Tray提供4个NIC用于Scale-out方向的扩展。每个Switch Tray包含1颗支持RoCE的高性能51.2Tbps以太网交换芯片,整个机柜提供8个Switch芯片。GPU和Switch芯片支持100G serdes。当前主流的GPU互联带宽为3.2Tbps,ETH-X整机柜GPU互联带宽为204.8Tbps。8个Switch Tray支持409.6Tbps的带宽,一半用于超节点柜内连接GPU,另一半的带宽用于背靠背连接旁边机柜的超节点或者通过L2 HB Switch做更大的HBD域Scale-up扩展。对于Intel Gaudi3 GPU,可以提供4.8Tbps的带宽,因此超节点机柜需要12个Switch Tray。同时,ETH-X也支持Switch Tray没有外部Scale-up扩展口的方案,所有serdes连接都用于柜内互联,这时候只需要4个2U高的Switch Tray(Gaudi3为6个)。
ETH-X对Scale-up网络特性的支持情况:
- 高带宽
ETH-X的每个GPU提供3.2Tbps(或4.8Tbps)的Scale-up连接带宽,同时通过PCIe对外提供400Gbps的Scale-out连接带宽,Scale-up带宽是Scale-out带宽的8~12倍。
- 低时延
ETH-X没有限定Switch Tray的芯片型号,可以采用Broadcom的Tomahawk5,也可以采用Marvell的Teralynx10,甚至还可以采用国产化的25.6T芯片2片进行设计。总体来说,Scale-up方向的Switch时延控制在纳秒级是大家的一个共识。同时ETH-X也借鉴了NVIDIA NVL72的经验,Switch Tray和Compute Tray之间采用的是更低成本和更低时延的电缆连接。
- 大内存空间
NVIDIA NVL72通过GPU-Switch-GPU的NVILink实现统一内存地址空间,通过GPU-CPU的NVLink C2C实现缓存一致性。而ETH-X的GPU-Switch- GPU之间为RoCE连接、GPU-CPU之间为PCIe连接,需要进一步的开发互通协议,向应用层提供支持Direct Copy、Direct Access以及UVA统一编址等内存语义,实现GPU之间的访存协议。
总结和展望
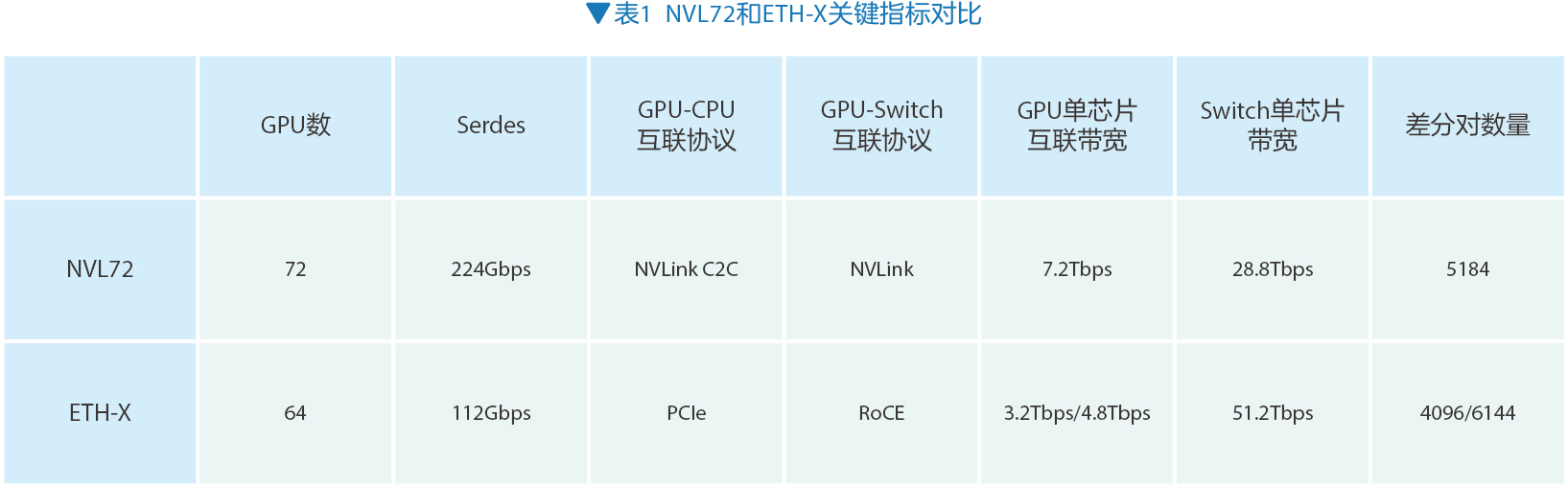
NVL72和ETH-X超节点都可以提供高带宽、低时延、大内存空间的Scale-up网络扩展。NVL72方案采用NVLink和NVLink C2C连接,超节点内的GPU之间的内存都可以互访。ETH-X采用开放的以太网解决方案,优点是生态开放,可以推广为ODCC组织的一个标准,不过由于没有NVLink这种类总线的协议,ETH-X后续还需要进行内存语义支持的开发。两种超节点的关键指标对比如表1所示。
NVL72凭借其先发优势,在国外OTT大厂中获得了较多的订单,展现出强大的市场竞争力。然而,它也存在一定的局限性,其基于私有协议的生态体系相对封闭,可能在一定程度上限制了更广泛的行业协作与创新。
ETH-X作为开放标准,在进度上稍落后于NVL72,这主要是由于公开标准的制定过程需要投入大量时间和精力。这一过程中不仅涉及复杂的技术讨论,还需在标准成员间进行多方面的协调与博弈,包括技术细节、商业利益以及战略方向等非技术因素。尽管如此,开放标准的特性为ETH-X带来了广阔的潜在应用空间和行业包容性。
独行快,众行远,NVL72和ETH-X作为当前超节点技术的两大代表,各自展现了独特的魅力。在未来的发展中,我们相信这两种技术将在各自的生态系统中绽放异彩,共同为超节点技术的发展书写精彩篇章。
.png)

.png)

.png)


