集中化BSS的探索
发布时间:2015-03-01
作者:吴名朝(中兴软创)
移动互联网、云计算、大数据的大潮正以排山倒海之势席卷而来,各种商业“野蛮人”,正举着互联网“跨界融合”的大刀,冲破原来的行业边界,闯入传统行业的前院,或者溜进他们的后花园。
具体到国内电信运营商,正在遭受OTT、微信、营改增、营销费用压缩、智能终端等的多重压力。划小、倒三角、集约运营、放权搞活、组织偏化、流程再造、逆向考核等深化改革的号角已经响彻天际。集中化BSS,也就是CRM和计费两个核心系统的横向融合与纵向集中,也慢慢浮出水面,不再像过去那样“犹抱琵琶半遮面”。
然而,国内运营商核心BSS系统的IT架构较之互联网行业更为封闭,而放眼全球电信运营商,多业务、多形态、高达十亿量级用户(每月千亿量级话单)的集中化支撑系统更无先例可循。
在这种大背景下,中兴软创组织BSS领域的精兵强将,对集中化BSS展开深入探讨和思考。
集中化BSS面临的问题
业务层面,系统集中将面临极为复杂的环境,不仅要承接过去,还要面向未来,要解决业务运营统一与分省经营历史的矛盾。
技术层面,要考虑多种模式并存,在线计费的高并发、快速响应需求,月度账务处理的大批量特性,订单的高并发交互等特点。
数据层面,一方面,集中后,系统需要管理接近10亿级的用户数,这些用户每月将产生千亿级的通话类、数据类、上网类等使用事件,将有千万级的订单交易产生,涉及百亿级的数据存取操作;另一方面,由于企业应用的业务逻辑层一直非常厚,对数据的使用方式多样化,很难找到一种具体的数据组织方式,能够同时满足多种业务需求。
基础设施层面,随着数据量和并发量的增加,存储资源、计算资源和网络资源的数量也呈数量级增加,必然导致基础设施组织方式和使用模式发生结构性变化。
在运维层面,随着数据、流量、存储资源、计算资源和网络资源的数量呈数量级递增,相应的配置工作、监控成本、故障数量将大大增加。
集中化BSS系统总体架构
考虑到全国集中后的大数据量、高并发、业务差异、不同模块计算模式差异和数据组织差异等特点,系统将采用云化架构,以松耦合的方式组织各域功能和数据(见图1)。
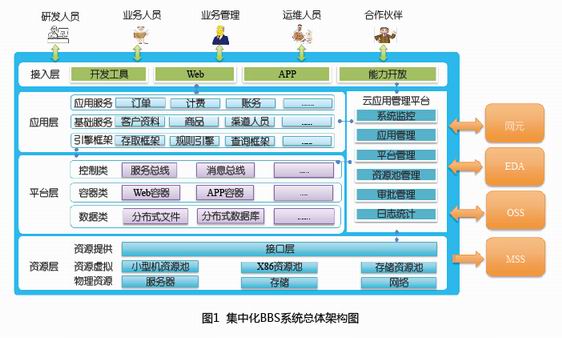
弹性伸缩高性能
分层化:实现界面、应用、数据、平台和资源层分离,每个层面可独立伸缩;模块化:层内各种能力以模块化的方式进行区隔,各个模块可以以自己合适的方式进行部署和伸缩;内存化:基于分布式缓存和内存数据库技术实现高性能;异步化:基于分布式消息队列,实现各个应用的松散耦合,避免性能木桶效应;智能化:基于服务总线、调度引擎,实现智能化的负载均衡和调度能力。
资源池化可共享
引入虚拟化技术,实现计算能力、储存能量和网络能力资源池化;实现底层能力按需分配和多方共享。
通用能力平台化
以平台化的方式封装分布式内存数据库、分布式缓存、分布式消息队列、分布式关系数据库、分布式文件系统、分布式服务总线、分布式ETL、分布式流式、批量计算引擎、分布式工作流等通用能力,满足业务部门快速推出业务的要求。
业务能力服务化
在应用模块化的基础上,以服务化、标准化的方式把能力统一注册到服务总线和能力开放平台上,使得新的业务能够以搭积木的方式进行构建,实现更加敏捷的业务支撑能力。
运维管理自动化
构建应用管理平台,实现功能部署、监控、诊断、调度和异常回复自动化。
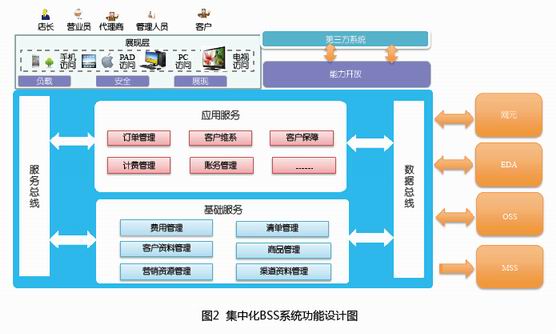
集中化BSS的系统功能架构
在功能层面,主要是考虑CRM和计费融合后,如何在多个模块之间共享数据和功能,图2是集中化BSS的系统功能设计图(图中未列出所有的功能)。在设计上,分为应用服务层和基础服务层。基础服务层统一管理BSS系统中的核心实体,以统一的方式向应用服务层提出基础的能力和数据。例如,通过统一的客户资料管理,可解决原来CRM/计费系统各自管理三户资料导致的数据冗余、数据不一致等问题。
集中化BSS数据架构
集中后,我们首先想到的就是数据量,当数据量出现暴增后,一个物理数据库难以支撑所有的数据,数据分片是一种选择。在具体部署策略上,会有很多种选择,例如垂直分片、水平分片、数据冗余、数据缓存等多种模式;聚焦到集中化BSS系统,考虑到不同的模块的数据量、数据使用的方式差别非常大,我们可以采取先垂直分片(以模块域为单位),也就是首先确定创建和维护数据的主模块,把相应的数据按照主模块的方式整理为订单类数据、客户类数据、计费类数据等,形成顶层数据部署架构,在顶层数据部署架构确定后,再在模块内部,按照数据量以及数据使用的需求进行二次分片,包括可能的二次垂直分片、水平分片、数据冗余等。这里我们以客户资料的数据分片为例,进一步解释数据部署架构的思路。
在全国集中后,数据量和访问的并发量将是巨大的,具体如下:将有约10亿客户/账户资料和10亿用户资料;销售品实例预计在20亿~30亿之间;每天约1千万订单,对资料的访问请求约5亿次,高峰时期约5万次/秒;每天约50亿话单,对资料的访问约500亿次,高峰时期约500万次/秒。
数据和流量分布也相对不均衡,例如最大的本地网约2000万用户,最小的本地网约30万用户;大的政企客户涉及10万的用户,100万销售品实例,而大部分个人客户仅对应1个用户,10个销售品实例。
应用对资料的访问存在一定的聚集特性,例如批价过程会一次性访问整个客户的所有历史资料;订单管理会访问整个用户的当前资料(包括用户基本信息、账务定制信息、功能产品信息等);而综合查询经常需要访问客户、用户、销售品实例的概要信息,这些概要信息需要整合客户、用户、销售品实例的关键信息。
因此,客户资料管理采用两级分片模式+数据分组的方式来组织数据,通过两级分片解决数据不均衡问题,通过数据分组解决数据访问的聚合倾向特征。
采用两级分片的模式解决数据不均衡问题:首先以本地网为依据,进行一级分片;在本地网内部,根据客户、用户、销售品实例的数量不同,进行二级分片。
采用数据分组的方式解决应用访问数据具有一定聚合特征的问题。不同的应用访问数据时,具有不一样的聚合特点;以客户(含账户)、用户和销售品为单位进行数据分组存储。
采用多级缓存模式解决各种应用对数据读取的多样化需求。在内存中,数据主要分为两块:主缓存和镜像缓存。
主缓存的数据分片模式和数据结构与物理数据库中的一致;所有的写入操作直接操作该缓存(MDB),由MDB通过日志回放的方式同步到物理数据库;同时,针对所有没有特殊需求的应用也可以通过主缓存读取相应的数据。
镜像缓存主要通过数据二次整合的方式,为计费、批价、综合查询等应用提供个性化的物化的数据视图,从而满足各个应用多样化的数据读取需求。
集中化BSS的应用架构
在应用架构层面,我们借鉴数据架构思路,采用按功能/模块域先进行垂直划分,在顶层垂直划分的整体模式下,在二级模块内部再根据应用模块的需要进行二次划分。因为业务需求的差异,集中化BSS每个模块的应用架构都不尽相同,这里我们以客户资料管理和计费管理为例,阐释集中BSS应用架构的设计思路。
客户资料管理应用架构
客户管理主要包括功能类组件、数据类组件和控制类组件三大块。
功能类应用:主要包括竣工提交、调整通知和入库处理等工程类应用和客户(含账户资料)查询、用户资料查询、套餐资料查询和群组资料查询等查询类功能。
数据类应用:负责客户资料管理涉及的数据的持久化存储和内存缓存。
控制类应用:主要包括消息中间件和分布式缓存中间件,通过这些中间件,实现数据同步和数据隔离等功能。
计费管理应用架构
计费应用是按无状态、无位置相关性的原则来设计的,理论上可以随意、混合部署,但考虑运维管理上的方便,建议计费应用根据应用类型划分子集群,分类管理:分成采集、预处理、批价、计费网关4大应用集群;在线和离线集群部署上分开;采集集群需要部署在能访问内外网段的主机上。
集中化BSS的引擎与框架
集中化BSS将以集约化的方式进行构建,具备一点服务全网的能力。通过云化、服务化和平台化方式,在一定程度上解决了集约化能力封装和提供的问题,但在实际研发和运维时,还是有很多非集约化的因素存在,为达到集中化的目标,还需要封装各种框架和引擎。我们梳理了统一存取框架、规则引擎、流程引擎、表单框架、分布式报表框架等多个引擎与框架,这里以统一对象存取框架为例进行介绍,其整体功能框架如图3。
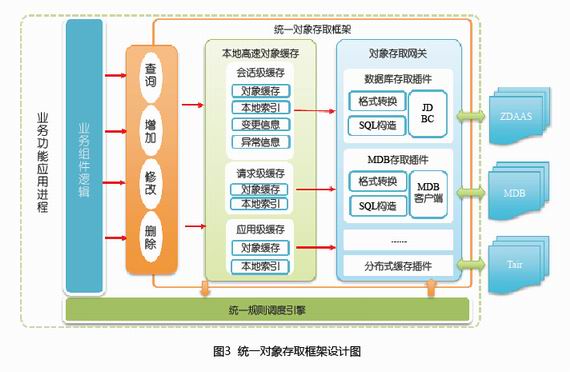
统一对象存取框架主要为操作型交互类应用提供统一的对象获取、缓存和保持框架,从应用程序中分离各种存取细节:
● 提供统一的和存储模式无关的对象存取API;
● 以本地高速缓存的方式实现统一的对象生命周期管理;
● 以数据存取网关+存取插件的方式支持和多种存取引擎对接;
● 向统一规则调度引擎提供对象变化通知。
本文从总体架构、功能架构、数据架构、应用架构、引擎与框架等多个角度介绍了我们对集中化BSS的一些思考和探索。集中化BSS需要考虑的问题还有很多,例如平台层面的各个平台组件、具体的流程和接口、系统的运维与监控等多个方面,因为篇幅关系,本文没有一一展开。集中化BSS是传统运营商互联网化的重要举措,而移动互联网最大的特点通过网络使得原来分散的客户聚集在一起,有了更多的话语权,正是这种买卖权力模式的重构引领着互联网化商业模式。因此,互联网公司在强调资源、运维、支撑集约的同时,也不断通过大数据探索本地化、国际化、社交化、场景化、碎片化、O2O等“多人多面”的去中心化模式。所以,运营商构建集中化BSS在考虑资源、建设、运维、品牌集中管理的同时,也要充分考虑因时间、地点、场景、竞争不同而引发的多样化需求。
.png)

.png)

.png)


