Development Trends of AI Computing Power
Release Date:2024-05-16
By Zhu Kun
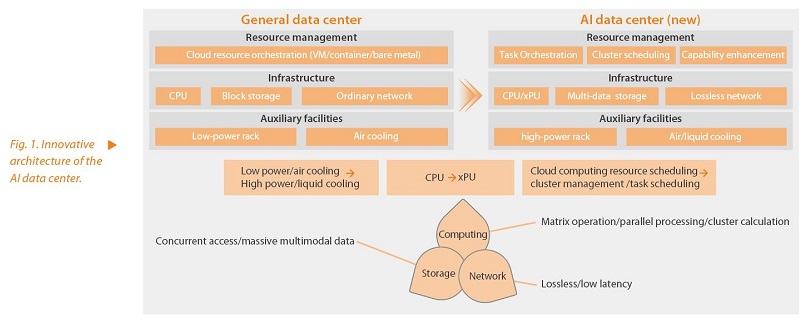
With the advent of ChatGPT, artificial intelligence (AI) has rapidly become a key force for social progress. The extensive application of AI technologies has brought great changes to our lives and work, relying heavily on robust computing infrastructure. AI training tasks and inference applications demand high-performance, large-scale parallelism, and low-latency interconnections, necessitating diverse requirements for computing, storage, and network interconnections. In addition, the demand for AI power aggregation also triggers innovation in the infrastructure management platform (Fig. 1).
AI Chips
In addition to the high-performance matrix operations required for AI model training and inference, larger parameter values in AI models necessitate greater memory capacity. Additionally, extensive data exchange among multiple AI chips demands high bandwidth and low latency in interconnection buses. Therefore, AI chips must meet three major requirements: computing power, memory, and interconnection buses.
In terms of computing power, AI uses machine learning technology based on multi-layer neural networks, requiring extensive matrix operations such as multiplication, convolution, and activation functions. Traditional CPUs have lengthy data flows, allocating more space to control and cache units, with computing units occupying only 25% of the space. Generally, there are just a few dozen arithmetic logic units (ALUs), with efficiency not being high in processing these parallelized and vectorized operations. Graphics processing units (GPUs), however, allocate 90% of the space to computing units, enabling parallel processing of dense data with thousands of ALUs. Since 2017, mainstream AI chip manufacturers have released AI GPUs dedicated to matrix computing acceleration, enhancing computing performance for large-model training. In addition to hardware, GPU manufacturers usually provide the corresponding development platforms like NVIDIA CUDA, allowing developers to directly program and optimize GPUs to fully utilize their computing capabilities.
In terms of memory, transformer model parameters increase by an average factor of 240 every two years, while AI memory capacity only doubles every two years, failing to keep pace with model growth. To address this, a feasible solution is the use of super nodes with unified memory addressing. For example, by customizing an AI server and forming a super node (including 256 GPUs and 256 CPUs) through high-speed interconnection technology, memory capacity can increase by 230 times. In addition, AI chips use the von-Neumann architecture where computing and storage are separated, leading to significant energy consumption (60% to 90%) during data migration. Estimating based on 60% of the maximum power consumption of H800 (700W), data migration consumes 420W. To solve this problem, the memory and computing integration technology fully integrates memory and computing, avoiding data migration and greatly improving energy efficiency.
Regarding interconnection buses, after 3D parallel splitting of AI models, data transmission between chips becomes essential. Tensor parallel (TP) transmission dominates transmission time, exceeding 90%. Test data shows that using the same number of servers to train GPT-3, compared to PCIe, reduces the transmission time of one micro-batch between adjacent GPUs from 246.1 ms to 78.7 ms, and overall training time from 40.6 days to 22.8 days. Therefore, the bandwidth of the interconnected bus becomes crucial.
Storage for AI Computing
At various stages of end-to-end development for AI model, innovation requirements have been proposed for storage, including:
- Multi-data storage: Multimodal datasets such as video, image, and audio bring requirements for diverse storage formats such as blocks, files, objects, and big data, as well as for protocol interworking.
- Massive storage: To ensure the precision of AI model training, the dataset is usually 2–3 times the size of the parameter values. In the current era of rapid development for AI models, expanding from 100 billion to one trillion, storage capacity serves as a crucial indicator.
- High concurrent performance: In the AI parallel training scenario, multiple training nodes need to read datasets simultaneously. During the training process, each training node needs to periodically save checkpoint to ensure system resilience for breakpoint training. The high performance of these read/write operations can greatly improve the efficiency of AI model training.
Therefore, for AI computing storage, it is necessary to provide multi-data storage capability and multi-protocol interworking capability for block (iSCSI), file (NAS), object (S3), and big data (HDFS). Performance can be improved through comprehensive software and hardware optimization. Hardware acceleration methods involve offloading storage interface protocols via DPUs, and performing deduplication, compression, and security operations, as well as automatic data tiering and partitioning based on popularity. Software optimization methods include distributed caching, parallel file access systems, and private clients. In addition, NFS over RDMA and GPUs can greatly reduce data access latency.
Lossless Network
The parallel computing nature of AI model training brings a large amount of communication overhead, making the network a key factor that restricts training efficiency. Lossless network is thus essential, requiring zero packet loss, high throughput, large bandwidth, stable low latency, and ultra-large-scale networking.
Currently, lossless network protocols are divided into IB and RoCE. The IB network, originally designed for high-performance computing (HPC), boasts low latency, high bandwidth, SDN topology management, rich networking topologies, and high forwarding efficiency. However, its industrial chain remains closed. RoCE, designed for a unified transport network, offers high bandwidth and network flexibility. It provides strong support for cloud-based services and promotes ecological openness. Therefore, RoCE is essential for localization. Nevertheless, its network performance and technology maturity lag behind IB, and latency requires further optimization based on chips.
Traditional network congestion and traffic control algorithms operate independently on both the client side and the network side. The network provides only coarse-grained congestion marking information, making it challenging to prevent congestion, packet loss, and queuing delays in high-throughput, full-load scenarios. Therefore, it is necessary to implement accurate and fast congestion control and traffic scheduling algorithms through client-network coordination to further enhance network performance.
In network topology, Fat-Tree CLOS and Torus rail multi-plane topologies are two mainstream solutions for addressing network congestion issues in network design. The Fat-Tree CLOS network enhances traditional tree network by maintaining a low convergence ratio of 1:1 for uplink bandwidth to downlink bandwidth, ensuring no blocking path between any two nodes. The Torus rail multi-plane network connects GPUs at the same location on different servers to the same group of switches, forming a rail plane. GPUs at different server locations are connected to different switches, creating multiple rail planes.
Resource Task Scheduling Platform
Unlike general computing resource management platforms that distribute resources to multiple tenants using virtual cloud technology, intelligent computing scenarios concentrate on aggregating computing power. In AI task training, hundreds of tasks and thousands of nodes may run simultaneously. Utilizing the task scheduling platform optimally matches tasks with available resources, minimizing queue wait time, maximizing parallel task operations, and achieving optimal resource utilization. Currently, there are two mainstream scheduling systems: Slurm and Kubernetes.
Slurm, primarily for task scheduling in HPC scenarios, is widely used by supercomputers (including Tianhe Computer) and computer clusters around the world. Kubernetes, a container orchestration platform, is used to schedule, automatically deploy, manage, and extend containerized applications. At present, Kubernetes and wider container ecosystems are increasingly mature, shaping a general computing platform and ecosystem.
In AI task scheduling, Slurm and Kubernetes face different challenges. The deep learning workload shares similarities with HPC, making Slurm suitable for managing machine learning clusters. However, Slurm is not part of the machine learning ecosystem developed around containers, so it is difficult to integrate AI platforms like Kubeflow into such environments. In addition, Slurm is complex to use and maintain. Conversely, Kubernetes is easier to use, integrates well with common machine learning frameworks, and sees increasing adoption for big model training. Yet, scheduling GPUs with Kubernetes may lead to prolonged resource idle time, resulting in low average cluster usage (about 20%). Resources can only be scheduled by card, lacking the ability to split, schedule by card type, or queue them.
Deployment Scenario
Due to the varying requirements of computing characteristics and deployment locations for pre-training basic AI models, fine-tuning industry AI models, and adapting AI models to customer scenarios, the intelligent computing center adopts a three-level deployment model (Fig. 2). This includes the Hub AI model training center, provincial training and inference integration resource pool, and edge training and inference AIO, aligned with the hierarchical architecture of operators’ computing data centers.
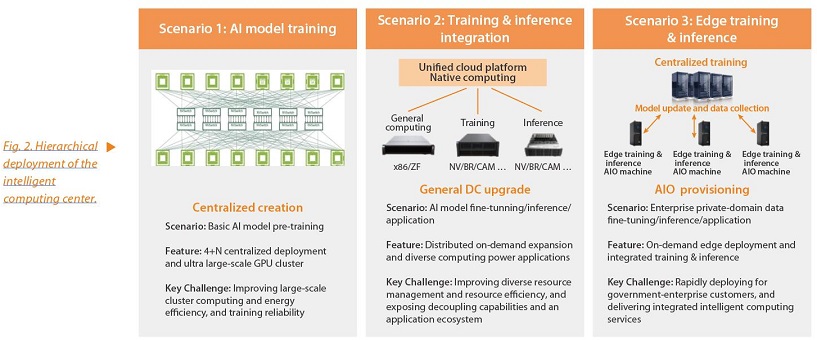
Operators bear the responsibility of improving innovation in key software and hardware technologies and building intelligent computing infrastructure. ZTE offers a full range of products spanning from IDCs, chips, servers, storage, data communications, to resource management platforms. Leveraging its extensive experience in the telecom and government-enterprise sectors, ZTE is poised to assist operators in realizing their ambitions in intelligent computing technology innovation and development.
Related Articles