ZTE’ s GPU Server Solution: Driving Digital Economy
Release Date:2024-05-16
By Zhou Zanxin
The AI field is undergoing a new round of rapid development, and the demand for generative AI computing power has skyrocketed. This trend is poised to become a new growth point and accelerator in the AI computing market.
In 2023, China’s GPU server market continued its rapid growth. According to IDC, the accelerated server market in China reached US$9.4 billion in 2023, an increase of 104% over the previous year, with shipments totaling 326k units. GPU-accelerated servers accounted for 92% of this market, reaching US$8.7 billion. IDC forecasts that by 2028, China’s accelerated server market will reach US$12.4 billion.
Requirements of AI Applications for GPU Servers
Compared with general servers, GPU servers offer several distinctive features:
- High-performance CPUs: A large number of computing resources are required for AI training and inference, necessitating high-performance CPUs to meet the processing requirements of large datasets.
- GPU accelerator cards: Compared with CPUs, GPUs excel in parallel computing , enabling them to accelerate the training and inference for deep learning models. A PCIe GPU can meet the requirements of most small and medium model training and inference applications. A single server usually supports four to eight GPU cards for parallel processing, enhancing computational performance and efficiency.
- Large-capacity memory: Sufficient capacity memory accelerates data flow and algorithm processing speed.
- High-bandwidth network interface: A high-speed network bandwidth (100GE or above) is required to transmit a large amount of data during the training process.
The rise of AI models brings force higher requirements for GPU servers. In particular, a large-scale model requires a huge amount of computing power to train, exceeding the capabilities of a single GPU. In this case, a single-server multi-card setup or multi-server clusters are needed to implement parallel training techniques, including tensor parallelism (TP), data parallelism (DP) and pipeline parallelism (PP). The specialized requirements of large models for GPU servers include:
- High-performance GPUs with large memory: A large model requires massive parallel computing capability, and a large number of parameters and gradient information need to be stored. Therefore, high-performance GPUs with large memory are required for training and inference.
- High-speed interconnection of GPUs within the server: The single-server multi-card setup utilizing the TP technique has exceptionally high requirements for the communication bandwidth between multiple GPUs within the server. An SXM/OAM GPU accelerator card supporting high-speed interconnection channels is required to facilitate high-speed interconnection among eight GPUs within a server, accelerating data transmission and model synchronization.
- High-performance interconnection network between servers: In multi-server clusters, the inter-machine parameter plane interconnection network needs to utilize a high-speed multi-track traffic aggregation architecture to give full play to the computing resources of GPU clusters. On the one hand, PCIe 5.0 slots are required to support 200/400G high-performance and low-latency IB/RoCE NICs. On the other hand, at least 10 NIC slots are required, with at least two NICs dedicated to the management and storage plane. GPUs and parameter plane NICs are configured in a 1:1 ratio to ensure that the parameter plane NICs connected to GPU cards in the same position across multiple GPU servers belong to the same switch, optimizing communication efficiency and accelerating parallel transmission.
- High-speed memory and storage: During the training of large AI models, rapid data read and write operations are crucial. It is necessary to support high-speed components such as DDR5 memory and NVMe SSD to enhance data transmission speed and reduce latency, thus improving the training efficiency.
- Liquid cooling: The ultra-high computing power density of SXM/OAM GPUs causes the power consumption of GPU servers to increase dramatically. Air cooling solutions restrict the computing power density of intelligent computing data centers, and fail to meet energy-saving and consumption reduction requirements. Liquid cooling becomes necessary.
Given the special requirements of AI model training and inference on GPU servers, dedicated GPU servers needs to be designed to support high-speed intra-sever and inter-sever networking. These servers should be appropriately configured and optimized to continuously adapt to new challenges and requirements.
ZTE GPU Server “3+2+3” Solution
To cope with the rapid development of AI, ZTE has launched the "3+2+3" GPU server solution, meeting the full-scenario AI application requirements of various customers (see Fig. 1).
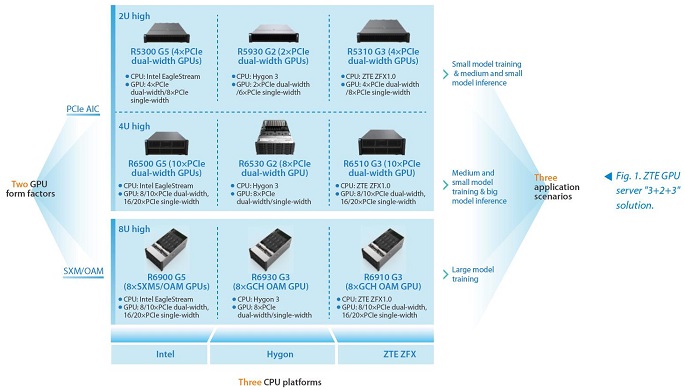
- Based on Three Major CPU Platforms
Tailored to different customer needs, ZTE has launched different types of GPU servers built on three major CPUs including mainstream X86 architecture CPUs, domestically-produced X86 architecture CPUs, and ZTE-developed ZFX CPU platforms.
- Supporting Two GPU Form Factors
The ZTE GPU server supports PCIe AIC GPUs as well as SXM/OAM GPUs designed for high-speed interconnection between cards, such as Nvidia SXM GPU accelerator cards or OAM GPU accelerator cards (Biren and Cambrian).
- Oriented to Three Application Scenarios
ZTE series GPU servers offer multiple configurations to meet the requirements of large-scale, medium-scale, and small-scale AI model training and inference scenarios.
For small model training and medium/small model inference scenarios, a general rack server is used. A single server can be configured with four dual/single-width full-height GPUs or six/eight single-width half-height GPUs, corresponding to the ZTE R53xx/59xx series servers.
In medium/small model training and large model inference scenarios, a dedicated PCIe AIC GPU server is employed. A single server can be configured with eight or 10 double-width, full-height and full-length GPUs or 16 or 20 single-width, full-height and full-length GPUs, corresponding to the ZTE R65xx series GPU servers.
For large model training scenarios, a dedicated SXM/OAM GPU server is used. A single server can be configured with eight SXM/OAM GPUs. To meet the multi-node cluster computing requirements, the GPU, parameter plane interconnection NIC and NVMe SSD are configured in a 1:1:1 setup, corresponding to the ZTE R69xx series GPU servers.
Conclusion
The GPU server market has become a high-growth segment within the server market, with its compound growth rate expected to remain high in the next few years. ZTE series GPU servers offer users high-quality and efficient computing power solutions, contributing to the establishment of a solid intelligent computing infrastructure that could further drive the growth of the digital economy.
Related Articles