High-Performance Network Designed for AI Model Training
Release Date:2024-05-16
By Yang Maobin
The popularity of ChatGPT has accelerated AI development from decision-making to generation, driving the need for high-performance networks for training AI models with billions of parameters. AI model training relies on distributed parallel computing, including data, pipeline, and tensor parallelism. To fully leverage GPU computing power, communication time overhead must be limited to within 5%. This necessitates a high-performance network for AI model training, characterized by zero packet loss, low latency, high throughput, large bandwidth, and large-scale networking.
Mainstream Solutions for High-Performance Networks
The two main high-performance network technologies used in AI model training scenarios are InfiniBand (IB) networks and RDMA over converged Ethernet version 2 (RoCEv2) networks.
The IB network, originating in the 1990s to replace the PCI bus technology, has become unexpectedly popular and widely used in high-performance computing and AI data centers. It implements packet lossless transmission through the credit flow control mechanism, and provides QoS for specific traffic optimization. Despite its advantages, its complex configuration, maintenance, and expansion, along with the need for special hardware and subnet managers, incur high costs. Therefore, the IB network is not as popular as Ethernet.
The RoCEv2 network, built upon Ethernet, allows remote direct memory access via encapsulated RDMA frames in IP/UDP packets. Data packets arriving at the RDMA NIC of the GPU server can be directly transmitted to the GPU memory, bypassing the CPU to reduce the delay. In addition, congestion control solutions like DCQCN are deployed to reduce RoCEv2 congestion and packet loss. Designed as a unified transport network, the RoCEv2 network caters to high bandwidth and elasticity needs, offering better support for cloud services and scalability, which is crucial for domestic high-performance networks.
RoCEv2 Network Congestion and Flow Control Analysis
In the RoCEv2 network, DCQCN is the most commonly used congestion control algorithm. It detects and indicates network congestion through the ECN flag on the switch. When congestion is detected, the switch adds ECN flags to data packets. RDMA NIC adjusts data transmission rates based on these flags via CNPs. The DCQCN algorithm is fair and efficient, ideal for high throughput, low-latency scenarios in high-performance computing and AI learning.
However, DCQCN also has the following disadvantages that cause network throughput to fluctuate between 50% and 60%:
- Inaccurate congestion indication: The 1-bit ECN flag lacks precision in distinguishing different levels of congestion.
- Slow and inaccurate rate adjustment: Only CNPs are used to adjust the rate and there is no feedback from other networks.
- No optimization based on traffic characteristics: The diverse characteristics of long and short flows as well as scheduling interval cycles are not considered.
- No consideration for multi-path balanced scheduling: More traffic is unevenly distributed, and multi-path bandwidth resources of the AI network are not fully utilized.
ZTE's Innovative Solution for RoCEv2 End-Network Collaboration
Traditional DCQCN networks are difficult to avoid congestion, packet loss, and delay issues in high-throughput, fully-loaded networks due to imprecise congestion flag data and separate end-side and network-side flow control mechanisms. To improve transmission performance in high-performance networks, ZTE proposes an innovative solution for RoCEv2 end-network collaboration. This solution implements accurate and fast congestion control and traffic scheduling algorithms through end-network collaboration, boosting RoCE network throughput to more than 90% (Fig. 1). It pioneers end-network collaboration and innovation in congestion control and accurate flow control.
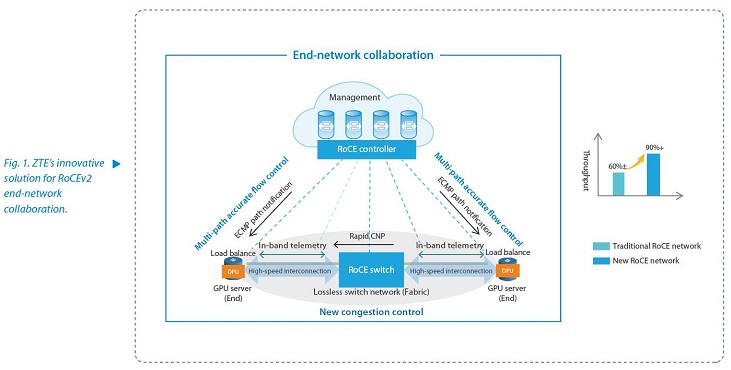
- New Congestion Control for End-Network Collaboration
The network devices promptly and accurately deliver link congestion information to the end side through fast CNP and in-band telemetry technologies to implement new congestion control.
—Fast CNP: In a traditional DCQCN network, when a network device is congested, related link data packets are marked with an ECN flag. Upon receiving the ECN flag, the destination NIC sends a CNP packet to the source NIC, which then adjusts the rate. This process takes a long time, leading to delayed rate adjustments. Therefore, the fast CNP solution is introduced. When detecting congestion, the intermediate switch immediately sends CNP packets containing detailed congestion information to the source NIC. The source NIC can use this information to adjust traffic accurately and quickly, thus rapidly alleviating network congestion.
—Accurate congestion control based on in-band telemetry: In the traditional DCQCN, the 1-bit ECN congestion indication fails to accurately convey link congestion levels, hindering accurate traffic control at the source. Therefore, an in-band telemetry-based solution is proposed to carry more path load information. The intermediate device fills available bandwidth, queue depth, timestamps, and sent byte counts in the telemetry packet. After collecting telemetry date from all network devices on the path, the end adjusts traffic accurately in real time based on a trained and optimized traffic scheduling algorithm. This optimization aims to achieve high throughput, low latency, and congestion-free end-to-end path traffic.
- Multi-Path Accurate Flow Control for End-Network Collaboration
The network side collaborates with the end side, leveraging the RoCE network’s equal-cost multi-path routing (ECMP) and multiple load balancing technologies to improve data transmission efficiency.
—ECMP end-network collaboration notification: The RoCE network in the AI model training data center uses the fat-tree CLOS architecture and has abundant ECMP paths. The RoCE controller comprehends the network topology, and synchronizes ECMP data to the end side to optimize data transmission and improve network efficiency.
—Load balancing tailored to traffic characteristics: The end selects load balancing technologies based on traffic characteristics (e.g., mouse flow, and elephant flow), routing packets through packet or source port hashing, and adjusts policies in real time to enhance data transmission efficiency.
As AI model parameters increase from 100 billion to one trillion and AI chip computing power remains limited, a 10,000-card intelligent computing cluster network becomes inevitable. Therefore, accurate end-network congestion control in large-scale networking scenarios poses a pressing industry challenge. ZTE’s innovative solution for RoCEv2 end-network collaboration aims to improve RoCE network throughout, enhance AI model training network performance, unlock additional AI computing power, and boost model training efficiency.
Related Articles